Sourcecode Documentation
The Spreadsheet Energy System Model Generator has a hierarchical structure and consists of a total of four work blocks, which in turn consist of various functions and subfunctions. The individual (sub-)functions are documented with docstrings according to the PEP 257 standard. Thus, the descriptions of functions, any information about input and output variables and further details can be easily accessed via the python help function.
Graphical User Interface (GUI). The GUI which is not part of the SESMGs four step represents the first part of the API Documentation. With the help of the Streamlit driven graphical user interface it is possible for the user to create a model definition using the Urban District Upscaling. Furthermore, an already created model definition (can also be created manually) can be passed to the SESMG with defined optimization parameters and thus a model optimization can be performed. Finally, newly created or already existing results can be visualized and evaluated.
Urban District Upscaling: With the help of the Urban District Upscaling Tool, a model definition can be automatically created based on a spreadsheet in which building-specific data as well as the possible investment decisions are entered (US-Input) and a spreadsheet containing technology-specific default values (standard_parameter). This model definition can then be passed on to the next work block via the Graphical User Interface (GUI). If required, the user can already use a simplification measure (clustering) when creating the model definition. In this case, different buildings are grouped together e.g. by their load profile via the cluster ID (column in the US-Input sheet).
Preprocessing. First of all, the Python library Pandas is used to read the input xlsx-spreadsheet file. Subsequently, an oemof time index (time steps for a time horizon with a resolution defined in the input file) is created on the basis of the parameters imported. This block is the basis for creating the model. The model does not yet contain any system components, these must be added in the following blocks. Afterwards, the system components defined in the xlsx model definition file which was filled by the user or the Urban District Upscaling Tool (described above) are created according to the oemof specifications, and added to the model. At first, the buses are initialized, followed by the sources, sinks, transformers, storages links and thermal network components. Reducing the computational effort is possible by using the data preparation algorithms or the pre model analysis functions of the SESMG.
Processing. In the processing section of the SESMG, the last precautions are taken on the energy system model before it is passed to the solver (both non-commercial solvers - CBC - and commercial solvers - GUROBI - are possible here). These precautions include the generation of possible conflicting objectives (for example area competitions) or also the generation of the emission equation for optimization against 2 optimization criteria.
Postprocessing. In the last block, the energy system results as returned from the solver are analyzed and prepared for further processing. Therefore several files like xlsx files holding the buses balances or csv files holding the total investment decisions are created. For the graphical analysis of the energy system’s results it’s energy amounts as well as it pareto front points are collected and delivered to the Graphical User Interface (GUI).
Graphical User Interface (GUI)
GUI/GUI_st_global_functions
Jan N. Tockloth - jan.tockloth@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de
- program_files.GUI_st.GUI_st_global_functions.check_for_dependencies(solver: str)[source]
Checks rather Graphviz, CBC or gurobi are installed.
- Parameters:
solver (str) – name of the solver chosen in the GUI sidebar
- program_files.GUI_st.GUI_st_global_functions.clear_GUI_main_settings(json_file_path: str) None[source]
Function to clear the GUI settings dict, reset it to the initial values and save in json path as variables.
- Parameters:
json_file_path (str) – internal path where json should be saved
- program_files.GUI_st.GUI_st_global_functions.create_cluster_simplification_index(input_value: str, input_output_dict: dict, input_value_index: str) None[source]
Creates the streamlit index for timeseries simplification param clustering as required to reload GUI elements with initial values since clustering index needs to set differently
- Parameters:
input_value (str) – name of the input variable in the input_output_dict
input_output_dict (dict) – global defined dict to which the indexes will be written in
input_value_index (str) – name of the output variable in the input_output_dict
- program_files.GUI_st.GUI_st_global_functions.create_result_directory(tail='') None[source]
Create a result directory and a SESMG folder in the user’s documents directory for storing JSON files and results.
- Parameters:
tail (str) – name of an additional folder in the result directory
This function creates a directory structure to store JSON files and results. It imports settings from ‘GUI_st_settings.json’ to determine the path structure. The ‘result_folder_directory’ value in the JSON defines the relative path. The directory structure is constructed based on the user’s documents directory.
- program_files.GUI_st.GUI_st_global_functions.create_simplification_index(input_list: list, input_output_dict: dict) None[source]
Creates the streamlit index for timeseries simplification params as required to reload GUI elements with initial values.
- Parameters:
input_list (list) – list with lists for each simplification with three columns: name of the index, list in which the index is defined regarding to the input cariable name, input variable name
input_output_dict (dict) – global defined dict to which the indexes will be written in
- program_files.GUI_st.GUI_st_global_functions.create_timeseries_parameter_list(GUI_main_dict: dict, input_value_list: list, input_timeseries_season: str) list[source]
Creates list of input variables as input preparation for run_semsg with appending input_timseries_season value.
- Parameters:
GUI_main_dict (dict) – global defined dict of GUI input variables
input_value_list (list) – list of input variables which will be written in a list from the GUI_main_dict
input_timeseries_season (str) – input value of the season drop down menu in the GUI
- Returns:
parameter_list + input_value_season (list) - list of timeseries simplification parameters
- program_files.GUI_st.GUI_st_global_functions.get_bundle_dir() str[source]
Get the path to the bundle directory.
This function determines and returns the path to the bundle directory where the program is located. It considers both the frozen state and the non-frozen state of the program.
- Returns:
bundle_dir (str) - The path to the bundle directory.
- program_files.GUI_st.GUI_st_global_functions.identify_win_solver_path(path_list: list) str[source]
Identify the path to a solver executable on a Windows system.
This function iterates through a list of paths, typically obtained using ‘where’ command on Windows, to find the first valid path to a solver executable. It removes the file extension (e.g., .exe or .bat) from the path and returns the cleaned path.
- Parameters:
path_list (list) – list of file paths to solver executables.
- Returns:
path_str (str) - cleaned path to the solver executable, without the file extension.
Example
>>> paths = ['C:\path\to\solver.exe', 'C:\another\solver.bat'] >>> identify_win_solver_path(paths) 'C:\path\to\solver'
- program_files.GUI_st.GUI_st_global_functions.import_GUI_input_values_json(json_file_path: str) dict[source]
Function to import GUI settings from am existing json file and save it as a dict.
- Parameters:
json_file_path (str) – file name to the underlying json with input values for all GUI pages
- Returns:
GUI_settings_cache_dict_reload (dict) - exported dict from json file including a (sub)dict for every GUI page
- program_files.GUI_st.GUI_st_global_functions.load_result_folder_list() list[source]
Load the folder names of the existing result folders.
- Returns:
existing_result_foldernames_list (list) - list of exsting folder names.
- program_files.GUI_st.GUI_st_global_functions.read_markdown_document(document_path: str, folder_path: str, main_page=True, fixed_image_width=None) list[source]
Using this method, texts stored in the repository in the form of markdown files can be used as the content of a streamlit page. To do this, the markdown file and the images it contains are loaded and then displayed in streamlit format.
- Parameters:
document_path (str) – path where the markdown file which will be displayed is stored
folder_path (str) – path where the images the to be displayed file contains are stored
main_page (bool) – boolean which differentiates rather the method is called from the main method or not since the main page content is the Readme reduced by the installation part
fixed_image_width (int) – sets the width of the image on default None as the max width or can be defined as an int for the st.image() function
- Returns:
readme_buffer (list) - list of markdown text which is educed by the parts between ## Quick Start ## SESMG Features & Releases based on the readme.md
- program_files.GUI_st.GUI_st_global_functions.run_SESMG(GUI_main_dict: dict, model_definition: str, save_path: str) None[source]
Function to run SESMG main based on the GUI input values dict.
- Parameters:
GUI_main_dict (dict) – global defined dict of GUI input variables
model_definition (str) – file path of the model definition to be optimized
save_path (str) – file path where the results will be saved
- program_files.GUI_st.GUI_st_global_functions.save_GUI_cache_dict(input_values_dict: dict, json_file_path: str) None[source]
Function to save a the cache dict as json.
- Parameters:
input_values_dict (dict) – name of the dict of input values for specific GUI page
json_file_path (str) – file name to the underlying json with input values
- program_files.GUI_st.GUI_st_global_functions.save_json_file(input_values_dict: dict, json_file_path: str) None[source]
Function to save a dict as json.
- Parameters:
input_values_dict (dict) – name of the dict
json_file_path (str) – file path to the underlying json
- program_files.GUI_st.GUI_st_global_functions.set_internal_directory_path() str[source]
Set the path for storing internal files based on the SESMG main (/ parenting) diretory.
This function determines and returns the path for storing internal files based on the settings specified in ‘GUI_st_settings.json’ file. The ‘result_folder_directory’ value in the JSON defines the relative path within the user’s documents directory.
- Returns:
res_internal_directory_path (str) - Path to the internal
.app folder in the SESMG directory
- program_files.GUI_st.GUI_st_global_functions.set_parenting_sesmg_result_path() str[source]
Set the path for storing SESMG files and the results based on settings.
This function determines and returns the path for storing files and results based on the settings specified in ‘GUI_st_settings.json’ file. The ‘result_folder_directory’ value in the JSON defines the relative path within the user’s documents directory.
- Returns:
res_parenting_folder_path (str) - Main path to the SESMG
directory
- program_files.GUI_st.GUI_st_global_functions.set_result_path() str[source]
Set the path for storing results based on the SESMG main (/ parenting) diretory.
This function determines and returns the path for storing results based on the settings specified in ‘GUI_st_settings.json’ file. The ‘result_folder_directory’ value in the JSON defines the relative path within the user’s documents directory.
- Returns:
res_folder_path (str) - path to the result directory
- program_files.GUI_st.GUI_st_global_functions.show_error_graph(base_path: str) None[source]
Search for and display the energy system structure graph in the Streamlit interface.
This function performs a recursive search starting from the base path to find a ‘graph.gv.png’ file. It is designed to work for both standard runs and Pareto optimizations by navigating through potential subdirectories.
- Parameters:
base_path (str) – Path to the result directory where the search starts
- Returns:
None
- program_files.GUI_st.GUI_st_global_functions.show_error_with_link() None[source]
Show an error message with additional information and a link to the troubleshooting website.
This function generates a markdown-formatted error message in the Streamlit interface, providing the user with a direct link to the official SESMG troubleshooting documentation.
- Returns:
None
Urban District Upscaling Tool
US_Tool/pre_processing
Gregor Becker - gregor.becker@fh-muenster.de Christian Klemm - christian.klemm@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de Oscar Quiroga - oscar.quiroga@fh-muenster.de
- program_files.urban_district_upscaling.pre_processing.append_component(sheets: dict, sheet: str, comp_parameter: dict) dict[source]
Within this method a component with the parameters stored in comp_parameter will be appended on the in sheets[sheet] stored pandas.DataFrame
- Parameters:
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sheet (str) – str which specifies which dict entry will be changed
comp_parameter (dict) – component parameters which will be appended as column on sheet
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.pre_processing.column_exists(building: Series, column: str) bool[source]
Method which is used to check rather the column exists (True) within the building Series or not (False).
- Parameters:
building (pandas.Series) – Series which contains the building data
column (str) – label of the investigated column
- Returns:
- (bool) - boolean which signalizes whether the column exists or not
- program_files.urban_district_upscaling.pre_processing.copying_sheets(paths: list, standard_parameters: ExcelFile, sheets: dict) dict[source]
In this method, the data sheets that need to be transferred from the US input table to the model definition are transferred. For this purpose, the return data structure “sheets” is processed and then returned to the main method.
- Parameters:
paths (list) – path of the upscaling input sheet file [0] path of the standard_parameter file [1] path to which the model definition should be created [2] path to plain sheet file (holding structure) [3]
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.pre_processing.create_building_buses_and_links(building: Series, central_electricity_bus: bool, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, all buses and links required for one building are created and attached to the “buses” and “links” dataframes in the sheets’ dictionary.
- Parameters:
building (pandas.Series) – Series containing the building specific parameters
central_electricity_bus (bool) – defines rather buildings can be connected to central electricity net or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- program_files.urban_district_upscaling.pre_processing.create_heat_pump_buses_links(building: Series, gchps: dict, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, all buses and links required for the heat pumps are created and attached to the “buses” and “links” dataframes in the sheet dictionary.
- Parameters:
building (pandas.Series) – pandas.Series holding the specific data of the considered building
gchps (dict) – dictionary containing the energy systems gchps
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- program_files.urban_district_upscaling.pre_processing.create_standard_parameter_comp(specific_param: dict, standard_parameter_info: list, sheets, standard_parameters: ExcelFile) dict[source]
creates a component with standard_parameters, based on the standard parameters given in the “standard_parameters” dataset and adds it to the “sheets”-output dataset.
- Parameters:
specific_param (dict) – dictionary holding the storage specific parameters (e.g. ng_storage specific, …)
standard_parameter_info (list) – list defining the component standard parameter label [0], the components type [1] and the index of the components standard parameter worksheets [2]
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- program_files.urban_district_upscaling.pre_processing.get_central_comp_active_status(central: DataFrame, technology: str) bool[source]
Method used to check if the central component technology is enabled.
- Parameters:
central (pandas.DataFrame) – pandas.DataFrame containing the central components’ data from the upscaling tool input file
technology (str) – central component to be checked
- Returns:
- (bool) - return rather the technology is active (True) or not (False)
- program_files.urban_district_upscaling.pre_processing.get_user_inserted_shortage_params(cost_column: str, emission_column: str, building: Series)[source]
Method to extract the building specific input for shortage costs or emissions.
- Parameters:
cost_column (str) – str containing the cost column label
emission_column (str) – str containing the emission column label
building (pandas.Series) – Series containing the upscaling table input row
- Returns:
costs (float) - float containing the extracted costs value
emissions (float) - float containing the extracted costs value
- program_files.urban_district_upscaling.pre_processing.load_input_data(plain_sheet: str, standard_parameter_path: str, us_input_sheet: str) -> (<class 'dict'>, <class 'pandas.core.frame.DataFrame'>, <class 'pandas.core.frame.DataFrame'>, <class 'pandas.core.frame.DataFrame'>, <class 'pandas.io.excel._base.ExcelFile'>)[source]
This method is used to convert the three ExcelFiles necessary for the upscaling tool into pandas structures and then return them to the main method.
- Parameters:
plain_sheet (str) – string containing the path to the plain sheet ExcelFile, the plain sheet is used to create an empty model definition file in which only the column names are entered.
standard_parameter_path – string containing the path to the standard parameter ExcelFile
us_input_sheet (str) – string containing the path to the upscaling tool input file
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
central (pandas.DataFrame) - DataFrame holding the US-Input sheets’ central component Spreadsheet
parcel (pandas.DataFrame) - DataFrame holding the US-Input sheets’ parcel Spreadsheet
tool (pandas.DataFrame) - DataFrame holding the US-Input sheets’ building data and building investment data
standard_parameters (pandas.ExcelFile) - pandas imported ExcelFile containing the non-building specific technology data
- program_files.urban_district_upscaling.pre_processing.read_standard_parameters(name: str, parameter_type: str, index: str, standard_parameters: ~pandas.io.excel._base.ExcelFile) -> (<class 'pandas.core.frame.DataFrame'>, <class 'list'>)[source]
searches the right entry within the standard parameter sheet
- Parameters:
name (str) – component’s name
parameter_type (str) – determines the technology type
index (str) – defines on which column the index of the parsed Dataframe will be set in order to locate the component’s name specific row
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Raise:
ValueError - Error if the searched component type does not exist
- Returns:
standard_param (pandas.Dataframe) - technology specific parameters of name
standard_keys (list) - technology specific keys of name
- program_files.urban_district_upscaling.pre_processing.represents_int(entry: str) bool[source]
Method which is used to check rather the entry can be converted into an integer.
- Parameters:
entry (str) – entry under investigation
- Returns:
- (bool) - boolean which signs rather the considered column is an integer or not
- program_files.urban_district_upscaling.pre_processing.urban_district_upscaling_pre_processing(paths: list, open_fred_list: list, clustering: bool, clustering_dh: bool) -> (<class 'dict'>, <class 'dict'>)[source]
The Urban District Upscaling Pre Processing method is used to systematically create a model definition for a few 10 to a few hundred buildings based on a US input sheet filled in by the user, which includes investment alternative selection and building specific data to determine consumption and renovation status, and a spreadsheet which includes technology specific standard data (standard_parameter).
- Parameters:
paths (list) – path of the upscaling input sheet file [0] path of the standard_parameter file [1] path to which the model definition should be created [2] path to plain sheet file (holding structure) [3]
open_fred_list – boolean whether to download open fred data [0], longitude of the area under investigation [1], latitude of the area under investigation [2]
clustering (bool) – boolean for decision rather the buildings are clustered spatially
clustering_dh (bool) – boolean for decision rather the district heating connection will be clustered cluster_id wise
- Returns:
sheets (dict) - dictionary containing the created model definition prepared to save as xlsx
worksheets (list) - list containing the sheet names of the created model definition
US_Tool/clustering
- program_files.urban_district_upscaling.clustering.clustering_information(building: list, sheets: dict, source_param: dict, storage_parameters: dict, transformer_parameters: dict, sheets_clustering: dict) -> (<class 'dict'>, <class 'dict'>, <class 'dict'>, <class 'dict'>)[source]
After the data of the assets that are within a cluster have been collected previously, they are clustered in this method.
- Parameters:
building (list) – list containing the building information from the US-Input sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
source_param (dict) – dictionary containing the cluster summed source information
storage_parameters (dict) – dictionary containing the collected storage information
transformer_parameters (dict) – dictionary containing the collected transformer information
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
- Returns:
source_param (dict) - dictionary containing the cluster summed source information
transformer_parameters (dict) - dictionary containing the collected transformer information
storage_parameters (dict) - dictionary containing the collected storage information
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.clustering.clustering_method(tool: DataFrame, sheets: dict, standard_parameters: ExcelFile, central_electricity_network: bool, clustering_dh: bool) dict[source]
This method represents the main algorithm of clustering within the US tool. For this purpose, based on the model definition resulting from the preprocessing, the data of the plants in a cluster are first collected and/or averaged, then deleted, and finally the resulting plant for the cluster is created.
- Parameters:
tool (pandas.Dataframe) – DataFrame containing the Energysystem specific parameters which result from the Upscaling Tool’s input file
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
central_electricity_network (bool) – bool which decides rather a central electricity exchange is possible or not
clustering_dh (bool) – bool which decides rather the cluster’s district heating connections are clustered or not
- Returns:
sheets (dict) - dictionary holding the clustered model definition’s data
- program_files.urban_district_upscaling.clustering.clustering_transformers(sheets: dict, sink_parameters: list, transformer_parameters: dict, cluster: str, standard_parameters: ExcelFile) dict[source]
In this method the buses and links for the connection of the clustered transformers as well as the clustered transformers themselves are created and attached to the return data structure “sheets”.
- Parameters:
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sink_parameters (list) – list containing the cluster’s sinks parameter (4) res_heat_demand, (5)com_heat_demand, (6) ind_heat_demand
transformer_parameters (list) – dict containing the cluster’s transformer parameters (index) technology each entry is a list where index 0 is a counter
cluster (str) – str containing the cluster’s ID
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.clustering.collect_building_information(cluster_ids: dict, cluster: str, sheets: dict, standard_parameters: ~pandas.io.excel._base.ExcelFile, sheets_clustering: dict, building_labels: list) -> (<class 'dict'>, <class 'list'>, <class 'dict'>, <class 'dict'>, <class 'dict'>)[source]
In this method, the building specific assets are collected cluster wise. This includes sinks, PV systems, home storages (electric and thermal) and heat supply systems.
- Parameters:
cluster_ids (dict) – dictionary holding the clusters’ buildings information which are represented by lists containing the building label [0], the building’s parcel ID [1] and the building type [2]
cluster (str) – Cluster ID
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
building_labels (list) – list containing the building labels of the energy system to be clustered
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
sink_parameters (list) - list containing clusters’ sinks information
source_param (dict) - dictionary containing the cluster summed source information
storage_parameters (dict) - dictionary containing the collected storage information
transformer_parameters (dict) - dictionary containing the collected transformer information
- program_files.urban_district_upscaling.clustering.create_cluster_components(standard_parameters: ExcelFile, sink_parameters: list, cluster: str, central_electricity_network: bool, sheets: dict, transformer_parameters: dict, source_param: dict, storage_parameters: dict, clustering_dh: bool) dict[source]
After previously collecting and or averaging the information of the components belonging to a cluster and deleting the components that are no longer needed, the cluster components are created in this method. The adapted model definition structure “sheets” is returned after the creation process.
- Parameters:
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
sink_parameters (list) – list containing clusters’ sinks information
cluster (str) – cluster ID
central_electricity_network (bool) – bool which decides rather a central electricity exchange is possible or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
transformer_parameters (dict) – dictionary containing the collected transformer information
source_param (dict) – dictionary containing the cluster summed source information
storage_parameters (dict) – dictionary containing the collected storage information
clustering_dh (bool) – bool which decides rather the cluster’s district heating connections are clustered or not
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.clustering.create_cluster_heat_bus(transformer_parameters: dict, clustering_dh: bool, sink_parameters: list, cluster: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method the heat bus of the cluster is created, this can be created with averaged district heating network values if desired by the user or is simply connected to the still existing buses of the buildings. The updated model definition is then returned as “sheets”.
- Parameters:
transformer_parameters (list) – dict containing the cluster’s transformer parameters (index) technology each entry is a list where index 0 is a counter
clustering_dh (bool) – bool which defines rather the district heating coordinates have to be clustered or not
sink_parameters (list) – list containing the cluster’s sinks parameter (4) res_heat_demand, (5) com_heat_demand, (6) ind_heat_demand
cluster (str) – str containing the cluster’s ID
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.clustering.get_dict_building_cluster(tool: ~pandas.core.frame.DataFrame) -> (<class 'dict'>, <class 'list'>)[source]
Method which creates a dictionary holding the Cluster ID and it’s buildings and returns it to the main method
- Parameters:
tool (pandas.Dataframe) – DataFrame containing the Energysystem specific parameters which result from the Upscaling Tool’s input file
- Returns:
cluster_ids (dict) - dict holding the Cluster ID buildings combination
- program_files.urban_district_upscaling.clustering.remove_buses(sheets: dict, sheets_clustering: dict, building_labels: list) dict[source]
remove no longer used buses
building specific gas bus
building specific electricity bus
building specific heat pump electricity bus
building specific pv bus
building specific oil bus
building specific pellet bus
- Parameters:
sheets (dict) – dictionary containing the pandas DataFrames containing the energy system’s data
sheets_clustering (dict)
building_labels (list) – list containing the energy system buildings labels to identify the buses to be deleted
- Returns:
sheets (dict) - updated dictionary without the not used buses
US_Tool/components/Bus
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Bus.calculate_average_shortage_costs(standard_parameters: ExcelFile, sink_parameters: list, total_annual_demand: float, fuel_type: str, electricity: bool)[source]
- program_files.urban_district_upscaling.components.Bus.check_rather_building_needs_pv_bus(building: Series) bool[source]
If the currently considered building has a PV potential area, the return value is true. If this is not the case, the return value is False.
- Parameters:
building (pandas.Series) – pandas.Series containing the currently investigated building’s row from the US Input sheet.
- Returns:
pv_bus (bool) - boolean deciding rather a pv bus will be added to the model definition file or not.
- program_files.urban_district_upscaling.components.Bus.create_building_electricity_bus_and_central_link(bus: str, sheets: dict, building: Series, standard_parameters: ExcelFile, central_electricity_bus: bool) dict[source]
In this method, the in-house electricity bus is created if the building has a pv potential surface and/or an electrical load profile is available for that building. If the user has enabled a local electricity exchange, the in-house electricity bus is connected to the local exchange via a link. These two components are added to the return “sheets” dictionary.
- Parameters:
bus (str) – string defining the bus type of the house intern electricity bus
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
building (pandas.Series) – pandas.Series containing the currently investigated building’s row from the US Input sheet.
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
central_electricity_bus (bool) – boolean which represents the users decision rather a local exchange of electricity is possible or not
- Returns:
sheets (dict): dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was updated within this method
- program_files.urban_district_upscaling.components.Bus.create_cluster_averaged_bus(sink_parameters: list, cluster: str, fuel_type: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, an average grid purchase price for natural gas and heat pump electricity is calculated. This is measured based on the share of the heat demand of a building type (RES, COM, IND) in the total heat demand of the cluster.
- Parameters:
sink_parameters (list) – list containing the cluster’s sinks parameter (4) res_heat_demand, (5) com_heat_demand, (6) ind_heat_demand
fuel_type (str) – str defining which type of buses will be clustered
cluster (str) – Cluster id
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Bus.create_cluster_electricity_buses(building: list, cluster: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
Method creating the building type specific electricity buses and connecting them to the main cluster electricity bus
- Parameters:
building (list) – List holding the building label, parcel ID and building type
cluster (str) – Cluster id
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Bus.create_pv_bus_and_links(building: Series, sheets: dict, standard_parameters: ExcelFile, central_electricity_bus: bool) dict[source]
In this method, the PV bus of the considered building is created and connected to the in-house electricity bus and, if available, to the central electricity bus. The created components are appended to the return data structure “sheets”, which represents the model definition at the end.
- Parameters:
building (pandas.Series) – Series containing the building specific parameters
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
central_electricity_bus – boolean representing the user’s decision rather a local electricity exchange is possible or not
- program_files.urban_district_upscaling.components.Bus.create_standard_parameter_bus(label: str, bus_type: str, sheets: dict, standard_parameters: ExcelFile, coords=None, shortage_cost=None, shortage_emission=None) dict[source]
Creates a bus with standard_parameters, based on the standard parameters given in the “standard_parameters” dataset and adds it to the “sheets”-output dataset.
- Parameters:
label (str) – label, the created bus will be given
bus_type (str) – defines, which set of standard param. will be given to the dict
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
coords (list) – latitude / longitude / dh column of the given bus used to connect a producer bus to district heating network
shortage_cost (float) – If the user wants to map a shortage price that differs from the standard parameter, this value != None. This will overwrite the value from the standard parameters.
shortage_emission (float) – If the user wants to map a shortage emission that differs from the standard parameter, this value != None. This will overwrite the value from the standard parameters.
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Bus.get_building_type_specific_electricity_bus_label(building: Series) str[source]
In this method, based on the building_type column, the distinction between RES, COM and IND is made.
- Parameters:
building (pandas.Series) – pandas.Series containing the currently investigated building’s row from the US Input sheet.
- Returns:
bus (str) - string holding the buildings electricity bus type
US_Tool/components/Central_components
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de Oscar Quiroga - oscar.quiroga@fh-muenster.de
- program_files.urban_district_upscaling.components.Central_components.central_components(central: ~pandas.core.frame.DataFrame, sheets: dict, standard_parameters: ~pandas.io.excel._base.ExcelFile) -> (<class 'dict'>, <class 'bool'>, <class 'bool'>)[source]
In this method, the central components of the energy system are added to the model definition, first checking if a heating network is foreseen and if so, creating the feeding components, and then creating Power to Gas and battery storage if defined in the US-Input sheet.
- Parameters:
central (pandas.Dataframe) – pandas Dataframe holding the information from the US-Input file “central” sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_chp(label: str, fuel_type: str, output: str, central_electricity_bus: bool, central_fuel_bus: bool, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, a central CHP unit with specified gas type is created, for this purpose the necessary data set is obtained from the standard parameter sheet, and the component is attached to the transformers sheet.
- Parameters:
label (str) – defines the central heating plant’s label
fuel_type (str) – string which defines the heating plants fuel type
output (str) – string containing the transformers output
central_electricity_bus (bool) – determines if the central power exchange exists
central_fuel_bus (bool) – defines rather a central fuel exchange is possible or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_heat_bus_components(central: DataFrame, sheets: dict, standard_parameters: ExcelFile, exchange_buses: dict) dict[source]
In this method, the components connected to a central heat bus are created and appended to the return dictionary sheets.
- Parameters:
central (pandas.Dataframe) – pandas Dataframe holding the information from the US-Input file “central” sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
exchange_buses (dict) – dictionary holding booleans indicating if the user has enabled electricity and/or naturalgas exchange
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_heat_component(label: str, comp_type: str, bus: str, exchange_buses: dict, sheets: dict, standard_parameters: ExcelFile, flow_temp: str, gchp_list: list) dict[source]
In this method, all heat supply systems are calculated for a heat input into the district heat network.
- Parameters:
label (str) – defines the central component’s label
comp_type (str) – defines the component type
bus (str) – defines the output bus which is one of the heat input buses of the district heating network
exchange_buses (dict) – defines rather the central exchange of the specified energy is possible or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
flow_temp (str) – flow temperature of the central heating system (district heating)
gchp_list – list containing [0] the gchp potential area, [1] the length of the vertical heat exchanger relevant for GCHPs and [2] the heat extraction for the heat exchanger referring to the location
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_heating_transformer(label: str, fuel_type: str, output: str, central_fuel_bus: bool, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, a central heating plant unit with specified gas type is created, for this purpose the necessary data set is obtained from the standard parameter sheet, and the component is attached to the transformers sheet.
- Parameters:
label (str) – defines the central heating plant’s label
fuel_type (str) – string which defines the heating plants fuel type
output (str) – str containing the transformers output
central_fuel_bus (bool) – defines rather a central fuel exchange is possible or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_heatpump(label: str, specification: str, create_bus: bool, central_electricity_bus: bool, output: str, sheets: dict, standard_parameters: ExcelFile, args: dict) dict[source]
In this method, a central heatpump unit is created, for this purpose the necessary data set is obtained from the standard parameter sheet, and the component is attached to the transformers sheet.
- Parameters:
label (str) – str containing the label of the heatpump to be created
specification (str) – string giving the information which type of heatpump shall be added.
create_bus (bool) – indicates whether a central heatpump electricity bus and further parameters shall be created or not.
central_electricity_bus (bool) – indicates whether a central electricity exists
output (str) – str containing the heatpump’s output bus label
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
args (dict) – dictionary containing additional arguments (area, flow_temp, length_geoth_probe, heat_extraction)
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_pv_st_sources(central: DataFrame, sheets: dict, standard_parameters: ExcelFile, electricity_exchange: bool) dict[source]
In this method, the bus link construct for connecting central sources (PV and ST) to the energy system is created. The sources are then created and finally the sheets dict is returned.
- Parameters:
central (pandas.Dataframe) – pandas Dataframe holding the information from the US-Input file “central” sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
electricity_exchange (bool) – boolean indicating if the user has enabled the electricity exchange between buildings
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_central_timeseries_sources(central: DataFrame, sheets: dict, standard_parameters: ExcelFile, electricity_exchange: bool) dict[source]
In this method, the user activated central timeseries sources their buses and links are created.
- Parameters:
central (pandas.Dataframe) – pandas Dataframe holding the information from the US-Input file “central” sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
electricity_exchange (dict) – boolean indicating if the user has activated the exchange of electricity between buildings
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Central_components.create_power_to_gas_system(label: str, output: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, a central power to gas system is created, for this purpose the necessary data set is obtained from the standard parameter sheet, and the components are attached to the transformers, the storages and the buses sheet.
- Parameters:
label (str) – str containing the label of the heatpump to be created
output (str) – define the heat output bus for the power to gas components
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
US_Tool/components/Insulation
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Insulation.create_building_insulation(building: dict, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, the U-value potentials as well as the building year-dependent U-value of the insulation types are obtained from the standard parameters to create the insulation components in the model definition.
- Parameters:
building (dict) – dictionary holding the building specific data
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
US_Tool/components/Link
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Link.add_cluster_naturalgas_bus_links(sheets: dict, cluster: str, standard_parameters: ExcelFile) dict[source]
In this method, the naturalgas bus of the cluster is connected to the central natural gas bus.
- Parameters:
cluster (str) – Cluster ID
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Link.create_central_electricity_bus_connection(cluster: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, clustered buildings are connected to the local electricity market. For this purpose, a link is created between the cluster power bus and the central power bus and, if available, another link between the cluster pv bus and the central power bus. These are attached to the return structure “sheets”.
- Parameters:
cluster (str) – Cluster id
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Link.create_cluster_pv_links(cluster: str, sheets: dict, sink_parameters: list, standard_parameters: ExcelFile) dict[source]
In this method, the PV bus of the cluster is connected to the central electricity bus, if the cluster power demand > 0, it is also connected to the cluster power bus.
- Parameters:
cluster (str) – Cluster ID
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sink_parameters (list) – list holding the cluster’s sinks information e. g. the total res electricity demand [0]
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Link.create_link(label: str, bus_1: str, bus_2: str, link_type: str, sheets, standard_parameters: ExcelFile) dict[source]
Creates a link with standard_parameters, based on the standard parameters given in the “standard_parameters” dataset and adds it to the “sheets”-output dataset.
- Parameters:
label (str) – label, the created link will be given
bus_1 (str) – label, of the first bus
bus_2 (str) – label, of the second bus
link_type (str) – needed to get the standard parameters of the link to be created
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Link.delete_non_used_links(sheets_clustering: dict, building_labels: list, sheets: dict) dict[source]
Within this method all non-clustered links which are no longer in use after the clustering process are removed and the
- Parameters:
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
building_labels (list) – list containing the building labels of the energy system to be clustered
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
US_Tool/components/Sink
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Sink.create_cluster_electricity_sinks(standard_parameters: ExcelFile, sink_parameters: list, cluster: str, central_electricity_network: bool, sheets: dict) dict[source]
In this method, the electricity purchase price for the respective sink is calculated based on the electricity demand of the unclustered sinks. For example, if residential buildings account for 30% of the cluster electricity demand, 30% of the central electricity purchase price is formed from the residential tariff. In addition, the inputs of the cluster sinks, if there is an electricity demand, are changed to the cluster internal buses, so that the energy flows in the cluster can be correctly determined again.
- Parameters:
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
sink_parameters (list) – list containing clusters’ sinks information
cluster (str) – Cluster ID
central_electricity_network – boolean which decides whether a central electricity exchange is possible or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Sink.create_electricity_sink(building: Series, area: float, sheets: dict, sinks_standard_param: DataFrame, standard_parameters: ExcelFile) dict[source]
In this method, the electricity demand is calculated either on the basis of energy certificates (area-specific demand values) or on the basis of inhabitants. Using this calculated demand the load profile electricity sink is created.
- Parameters:
building (pandas.Series) – building specific data which were imported from the US-Input sheet
area (float) – building gross area
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sinks_standard_param (pandas.DataFrame) – sinks sheet from standard parameter sheet
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Sink.create_heat_sink(building: Series, area: float, sheets: dict, sinks_standard_param: DataFrame, standard_parameters: ExcelFile) dict[source]
In this method, the heat demand is calculated either on the basis of energy certificates (area-specific demand values) or on the basis of inhabitants. Using this calculated demand the load profile heat sink is created.
- Parameters:
building (pandas.Series) – building specific data which were imported from the US-Input sheet
area (float) – building gross area
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sinks_standard_param (pandas.DataFrame) – sinks sheet from standard parameter sheet
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Sink.create_sink_ev(building: Series, sheets: dict, standard_parameters: ExcelFile) dict[source]
For the modeling of electric vehicles, within this method the sink for electric vehicles is created.
- Parameters:
building (pandas.Series) – building specific data which were imported from the US-Input sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Sink.create_sinks(building: Series, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, the sinks necessary to represent the demand of a building are created one after the other. These are an electricity sink, a heat sink and, if provided by the user (distance of Electric vehicle > 0), an EV_sink. Finally they are appended to the return structure “sheets”.
- Parameters:
building (pandas.Series) – building specific data which were imported from the US-Input sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Sink.create_standard_parameter_sink(sink_type: str, label: str, sink_input: str, annual_demand: float, sheets: dict, standard_parameters: ExcelFile) dict[source]
Creates a sink with standard_parameters, based on the standard parameters given in the “standard_parameters” dataset and adds it to the “sheets”-output dataset.
- Parameters:
sink_type (str) – needed to get the standard parameters of the link to be created
label (str) – label, the created sink will be given
sink_input (str) – label of the bus which will be the input of the sink to be created
annual_demand (float) – Annual demand previously calculated by the method provided for the considered sink type, representing the energy demand of the sink.
sheets – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets :type sheets: dict
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Sink.sink_clustering(building: list, sink: Series, sink_parameters: list) list[source]
In this method, the current sinks of the respective cluster are stored in dict and the current sinks are deleted. Furthermore, the heat buses and heat requirements of each cluster are collected in order to summarize them afterwards.
- Parameters:
building (list) – list containing the building label [0], the building’s parcel ID [1] and the building type [2]
sink (pandas.Series) – One column of the sinks sheet
sink_parameters (list) – list containing clusters’ sinks information
TODO: share sinks are currently clustered together with the cluster heat demands.
- Returns:
sink_parameters (list) - list containing clusters’ sinks information which were modified within this method
US_Tool/components/Source
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Source.cluster_sources_information(source: ~pandas.core.series.Series, source_param: dict, azimuth_type: str, sheets: dict) -> (<class 'dict'>, <class 'dict'>)[source]
Collects the source information of the selected type, and inserts it into the dict containing the cluster specific sources data.
- Parameters:
source (pandas.Series) – Dataframe containing the source under investigation
source_param (dict) – dictionary containing the cluster summed source information
azimuth_type (str) – defines the celestial direction of the source to be clustered
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
source_param (dict) - dict extended by a new entry
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.create_cluster_sources(source_param: dict, cluster: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
This method is used to create the clustered sources, which are divided into 8 cardinal directions with averaged parameters.
- Parameters:
source_param (dict) – dictionary containing the cluster summed source information
cluster (str) – Cluster id
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.create_competition_constraint(limit: float, label: str, roof_num: str, types: list, sheets: dict, standard_parameters: ExcelFile) dict[source]
Using the create competition constraint method, the area competition between a PV and a solar thermal system is added to the competition constraints spreadsheet. This is also done via the return structure “sheets”, which finally represents the model definition.
- Parameters:
limit (float) – max available roof area which can rather be used for photovoltaic or solar thermal sources
label (str) – building label
roof_num (str) – roof part id
types (list) – list containing component type labels. Necessary since the labels for (de)central components are different.
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.create_source(source_type: str, roof_num: str, building: Series, sheets: dict, standard_parameters: ExcelFile, st_output=None, min_invest='0') dict[source]
In this method, the parameterization of a source component is performed. Then, the modifiable attributes are merged with those stored in the standard parameters of the SESMG. Finally, the component is created and attached to the return data structure “sheets” from which the model definition is created.
- Parameters:
source_type (str) – define rather a photovoltaic or a solar thermal source has to be created
roof_num (str) – roof part number
building (pandas.Series) – building specific data (e.g. azimuth, surface tilt etc.)
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
st_output (str) – str containing the solar thermal output bus which is used for the connection to district heating systems
min_invest (str) – If there is already an existing plant, the user can specify its capacity. This capacity value is passed to the algorithm via min_invest and represents the entry for “min. investment capacity”.
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.create_sources(building: Series, clustering: bool, sheets: dict, standard_parameters: ExcelFile, st_output=None, central=False) dict[source]
Algorithm which creates a photovoltaic- and a solar thermal source as well as the resulting competition constraint for a roof part under consideration
- Parameters:
building (pandas.Series) – Series containing the building specific parameters
clustering (bool) – boolean which defines rather the resulting energy system is spatially clustered or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
st_output (str) – str containing the solar thermal output bus which is used for the connection to district heating systems
central (bool) – parameter which defines rather the source is a central source (True) or a decentral one (False)
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.create_timeseries_source(sheets: dict, label: str, output: str, standard_parameters: ExcelFile) dict[source]
This method can be used to create a time series source. This source receives the investment data specified in the standard parameters and the time series given by the user in the US input sheet.
Warning: Currently, only one type of timeseries source can be used, since the “timeseries_source” row in the standard parameters is explicitly used. In the upcoming commits it will be implemented that also the use of multiple types will be possible.
- Parameters:
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
label (str) – component label
output (str) – output bus label
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.sources_clustering(source_param: dict, building: list, sheets: dict, sheets_clustering: dict) -> (<class 'dict'>, <class 'dict'>)[source]
In this method, the information of the photovoltaic and solar thermal systems to be clustered are collected, and the systems whose information has been collected are deleted.
- Parameters:
source_param (dict) – dictionary containing the cluster summed source information
building (list) – list containing the building label [0], the building’s parcel ID [1] and the building type [2]
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
- Returns:
source_param (dict) - dict extended by a new entry
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Source.update_sources_in_output(building: Series, sheets_clustering: dict, cluster: str, sheets: dict) dict[source]
In this method, the input and output buses of the source components are corrected to the cluster buses. For this purpose, it is checked whether a building label is present in the input or output. Finally, the return data structure “sheets” is updated.
- Parameters:
building (pandas.Series) – Series containing the building specific parameters
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
cluster (str) – Cluster ID
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
US_Tool/components/Storage
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Storage.building_storages(building: dict, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, the investment alternatives for in-house storage (batteries or thermal storage) are created and attached to the return data structure “sheets”.
- Parameters:
building (dict) – dictionary containing the building specific parameters
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Storage.cluster_storage_information(storage: ~pandas.core.series.Series, storage_parameter: dict, storage_type: str, sheets: dict) -> (<class 'dict'>, <class 'dict'>)[source]
Collects the transformer information of the selected type, and inserts it into the dict containing the cluster specific transformer data.
- Parameters:
storage (pd.DataFrame) – Dataframe containing the storage under investigation
storage_parameter (dict) – dictionary containing the cluster summed storage information
storage_type (str) – storage type needed to define the dict entry to be modified
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
storage_parameter (dict) - dictionary holding the collected storage information
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Storage.create_cluster_storage(storage_type: str, cluster: str, storage_parameter: dict, sheets: dict, standard_parameters: ExcelFile) dict[source]
This method is used to create the clustered storages.
- Parameters:
storage_type (str) – str which defines the storage type to be created within this method
storage_parameter (dict) – dictionary containing the cluster summed source information
cluster (str) – Cluster id
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Storage.create_storage(building_id: str, storage_type: str, de_centralized: str, sheets: dict, standard_parameters: ExcelFile, min_invest='0') dict[source]
Sets the specific parameters for a storage, and creates them afterwards.
- Parameters:
building_id (str) – building label
storage_type (str) – string which defines which storage type will be created
de_centralized (str) – string which differentiates rather the created storage will be placed in a building (building) or central (central)
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
min_invest (str) – if the user’s input contains an already existing storage it’s capacity is the min investment value of the storage to be created
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Storage.storage_clustering(building: list, sheets_clustering: dict, storage_parameter: dict, sheets: dict)[source]
Main method to collect the information about the storage (battery, thermal storage), which are located in the considered cluster.
- Parameters:
building (list) – list containing the building label [0], the building’s parcel ID [1] and the building type [2]
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
storage_parameter (dict) – dictionary containing the collected storage information
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
US_Tool/components/Transformer
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.urban_district_upscaling.components.Transformer.building_transformer(building: dict, p2g_link: bool, sheets: dict, standard_parameters: ExcelFile) dict[source]
In this method, the transformer investment options that can be applied to a considered building by the user are created. This includes ASHP, Gas heating system, Electric heating system, oil heating system and woodstove. In the creation process, these are attached to the return data structure “sheets”, which in the end will represent the model definition spreadsheet.
- Parameters:
building (dict) – dictionary holding the building specific data
p2g_link (bool) – boolean defining rather a p2g system which creates a central naturalgas bus exists or not
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Transformer.cluster_transformer_information(transformer: ~pandas.core.frame.DataFrame, cluster_parameters: dict, technology: str, sheets: dict) -> (<class 'dict'>, <class 'dict'>)[source]
Collects the transformer information of the selected type, and inserts it into the dict containing the cluster specific transformer data.
- Parameters:
transformer (pandas.DataFrame) – Dataframe containing the transformer under investigation
cluster_parameters (dict) – dictionary containing the cluster summed transformer information
technology (str) – transformer type needed to define the dict entry to be modified
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
- Returns:
cluster_parameters (dict) - dictionary holding the clustered information of the deleted transformers
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Transformer.create_cluster_transformer(technology: str, cluster_parameters: dict, cluster: str, sheets: dict, standard_parameters: ExcelFile) dict[source]
After collecting the attributes of the building specific transformers and deleting them, this method creates the clustered transformer components and appends them to the return data structure “sheets”.
- Parameters:
technology (str) – str containing the transformer type
cluster_parameters (list) – dict containing the cluster’s transformer parameters (index) technology each entry is a list where index 0 is a counter
cluster (str) – str containing the cluster’s ID
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Transformer.create_gchp(tool: ~pandas.core.frame.DataFrame, parcels: ~pandas.core.frame.DataFrame, sheets: dict, standard_parameters: ~pandas.io.excel._base.ExcelFile) -> (<class 'dict'>, <class 'dict'>)[source]
Method that creates a GCHP and its buses for the parcel and appends them to the sheets return structure.
- Parameters:
tool (pandas.DataFrame) – DataFrame containing the building data from the upscaling tool’s input file
parcels (pandas.DataFrame) – DataFrame containing the energy system’s parcels as well as their size
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
- Returns:
gchps (dict) - dictionary holding the gchp label area combination
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Transformer.create_transformer(label: str, transformer_type: str, sheets: dict, standard_parameters: ExcelFile, de_centralized: str, flow_temp: str, category='', building_type=None, area='0', fuel_type='None', output='None', min_invest='0', length_geoth_probe='0', heat_extraction='0') dict[source]
Sets the specific parameters for a transformer component, creates them and appends them to the return data structure “sheets” afterwards.
- Parameters:
transformer_type (str) – string containing the type of transformer which has to be created
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
standard_parameters (pandas.ExcelFile) – pandas imported ExcelFile containing the non-building specific technology data
flow_temp (str) – flow temperature of the heating system which is necessary for the COP calculation of heat pumps etc.
building_type (str) – building type is used to define the shortage costs of heatpump electricity, gas, oil etc.
area (str) – potential area for gchps
label (str) – since this method is used to create decentral as well as central transformer components the label specifies the first part of the components label.
fuel_type (str) – with the help of the fuel_type attribute the transformer’s fuel type is chosen
output (str) – within the output attribute a transformer individual output bus label can be set. This attribute does not have to be filled for each transformer type which is the reason for the standard value.
min_invest (str) – if the user’s input contains an already existing transformer it’s capacity is the min investment value of the transformer to be created
len_geoth_probe (str) – length of the vertical heat exchanger relevant for GCHPs
heat_extraction (str) – heat extraction for the heat exchanger referring to the location
- Returns:
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
- program_files.urban_district_upscaling.components.Transformer.get_technology_dict(fuel_type: str, label: str, output: str, de_centralized: str, transformer_type: str, category: str)[source]
- program_files.urban_district_upscaling.components.Transformer.transformer_clustering(building: list, sheets: dict, sheets_clustering: dict, cluster_parameters: dict) -> (<class 'dict'>, <class 'dict'>)[source]
Main method to collect the information about the transformer (gasheating, ashp, gchp, electric heating, air-to-air heatpumps), which are located in the considered cluster.
- Parameters:
building (list) – list containing the building information from the US-Input sheet
sheets (dict) – dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets
sheets_clustering (dict) – copy of the model definition created within the pre_processing.py
cluster_parameters (dict) – dictionary containing the collected transformer information
- Returns:
cluster_parameters (dict) - dictionary containing the collected transformer information
sheets (dict) - dictionary containing the pandas.Dataframes that will represent the model definition’s Spreadsheets which was modified in this method
Preprocessing
Preprocessing/create_energy_system
Functions for creating an oemof energy system.
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.create_energy_system.define_energy_system(nodes_data: dict) -> (<class 'oemof.solph._energy_system.EnergySystem'>, <class 'dict'>)[source]
Creates an energy system with the parameters defined in the given .xlsx-file. The file has to contain a sheet called “energysystem”, which has to be structured as follows:
start_date
end_date
temporal resolution
YYYY-MM-DD hh:mm:ss
YYYY-MM-DD hh:mm:ss
h
- Parameters:
nodes_data (dict) – dictionary containing data from excel model definition file
- Returns:
esys (oemof.solph.Energysystem) - oemof energy system
nodes_data (dict) - dictionary containing data from excel model definition file after the timestamps of timeseries and weather data sheet have been changed
- program_files.preprocessing.create_energy_system.import_model_definition(filepath: str, delete_units=True) dict[source]
Imports data from a spreadsheet model definition file.
The excel sheet has to contain the following sheets:
energysystem
buses
transformers
sinks
sources
storages
links
time series
weather data
competition constraints
insulation
district heating
pipe types
- Parameters:
filepath (str) – path to excel model definition file
delete_units (bool) – boolean which defines rather the unit row in the imported spreadsheets is removed or not
- Raises:
FileNotFoundError - excel spreadsheet not found
- Returns:
nodes_data (dict) - dictionary containing excel sheets
Preprocessing/data_preparation
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation.append_timeseries_to_weatherdata_sheet(nodes_data: dict) DataFrame[source]
Merges the time series of the weather data set and the time series. This allows the weather data and time series to be processed together for cluster algorithms, reducing the error-proneness of separate processing.
- Parameters:
nodes_data (dict) – dictionary containing the data of the user’s model definition file
- Returns:
nodes_data [“timeseries”] (pandas.core.frame.DataFrame) - DataFrame containing the updated model definition timeseries data
- program_files.preprocessing.data_preparation.calculate_cluster_means(data_set: DataFrame, cluster_number: int, cluster_labels, period: str) DataFrame[source]
Determines weather averages of the individual clusters for a weather dataset, based on predetermined cluster allocation. Caution: weather data set must be available in hourly resolution!
- Parameters:
data_set (pandas.DataFrame) – data_set, the clusters should be applied to
cluster_number (int) – Number of clusters
cluster_labels (np.array) – Chronological list, which days of the weather data set belongs to which cluster
period (str) – defines rather days or weeks were selected
- Returns:
prep_data_set (pandas.core.frame.Dataframe) - pandas dataframe containing the prepared weather data set
- program_files.preprocessing.data_preparation.extract_single_periods(data_set: DataFrame, column_name: str, period: str) list[source]
Extracts individual periods of a certain column of a weather data set as lists. Caution: weather data set must be available in hourly resolution!
- Parameters:
data_set (pandas.DataFrame) – weather data set to be extracted
column_name (str) – column name of which the extraction should be applied
period (str) – indicates what kind of periods shall be extracted. Possible arguments: “days”, “weeks”, “hours”.
- Returns:
cluster_vectors (list) - list, containing a list/vector for every single day
- program_files.preprocessing.data_preparation.slp_sink_adaption(nodes_data: dict) None[source]
calculates the standard load profile timeseries, saves them to the timeseries data-sheet and changes the timeseries-reference for the respective sinks within the sinks-sheet.
This step is required, so that the slp-timeseries will be considered during the timeseries adaptions.
- Parameters:
nodes_data (dict) – dict containing the data from the user’s model definition
- program_files.preprocessing.data_preparation.timeseries_adaption(nodes_data: dict, clusters: int, cluster_labels: array, period: str) None[source]
In this method, the cluster mean is calculated first and then the timestamps of the timeseries sheet are adjusted. The newly created timeseries sheet is set as the timeseries sheet for the nodes data dictionary in the last step.
- Parameters:
nodes_data (dict) – system parameters imported from the users model definition spread sheet
clusters (int) – Number of clusters
cluster_labels (np.array) – Chronological list, which days of the weather data set belongs to which cluster
period (str) – defines rather hours, days or weeks were selected
- program_files.preprocessing.data_preparation.timeseries_preparation(timeseries_prep_param: list, nodes_data: dict, result_path: str) float[source]
Evaluates the passed parameters for timeseries preparation and starts the corresponding simplification/clustering algorithm.
- Parameters:
timeseries_prep_param (list) – List of timeseries preparation parameters with the scheme [algorithm, cluster_index, cluster_criterion, cluster_period, cluster_season]
nodes_data (dict) – Dictionary containing the energy systems resulting from the user’s model definition
result_path (str) – path where the modified model definition file will be stored after timeseries adaption
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation.variable_costs_date_adaption(nodes_data: dict, clusters: int, period: str) float[source]
To be able to work with the adapted weather data set some parameters from nodes_data must be changed.
- Parameters:
nodes_data (dict) – dict containing the model definition’s spreadsheets data
clusters (int) – Number of clusters
period (str) – defines rather hours, days or weeks were selected
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
Preprocessing/data_preparation/averaging
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation_algorithms.averaging.mean_adapt_timeseries_weatherdata(clusters: int, cluster_labels: list, period: str, nodes_data: dict) float[source]
Using this method, the mean values of the clusters are formed and then cost values as well as time series and weather data are adjusted to the new data set length.
- Parameters:
clusters (int) – number of clustered chosen by the user’s input
cluster_labels (list) – list holding the cluster labels represented by integers between 0 and (clusters - 1)
period (str) – str holding the user’s period decision
nodes_data – dictionary holding the user’ model model definition spreadsheet
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation_algorithms.averaging.timeseries_averaging(cluster_period: str, days_per_cluster: int, nodes_data: dict, period: str) float[source]
Averages the values of the time series, how many values are averaged is defined by the variable clusters.
- Parameters:
cluster_period (str) – contains the gui input of the chosen period type (possible entries: hours, days, weeks)
days_per_cluster (int) – contains the gui input of the chosen index (possible entries: 1 - 365)
nodes_data (dict) – dictionary containing the excel worksheets from the used model definition workbook
period (str) – defines rather days or weeks were selected
- Raise:
ValueError - Error raised if the chosen period is not supported
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
Preprocessing/data_preparation/downsampling
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation_algorithms.downsampling.timeseries_downsampling(nodes_data: dict, n_timesteps: int) float[source]
uses every n-th period of timeseries and weather data
- Parameters:
nodes_data (dict) – system parameters
n_timesteps (int) – defines which period is chosen
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation_algorithms.downsampling.timeseries_downsampling2(nodes_data: dict, n_timesteps: int) float[source]
cuts every n-th period of timeseries and weather data
- Parameters:
nodes_data (dict) – system parameters
n_timesteps (int) – defines which period is cut
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
Preprocessing/data_preparation/heuristic_selection
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation_algorithms.heuristic_selection.hierarchical_selection(nodes_data: dict, scheme: str, period: str, seasons: int) float[source]
Algorithm for the hierarchical selection of representative time periods of a weather data set. In this embodiment, the following representative periods are selected for every season (winter, spring, summer, fall) are selected:
Week containing the coldest temperature of the season
Week with the lowest average sun duration
Week containing the warmest temperature of the season
Week with the highest average sun duration
- Parameters:
nodes_data (dict) – SESMG-nodes data, containing weather data, energy system parameters and timeseries
scheme (str) – ID of heuristic selection scheme to be applied
period (str) – specifies whether ‘days’ or ‘weeks’ are applied as heuristic selection reference periods
seasons (int) – number of seasons for hierarchical selections, e.g. 12 for months or 4 for annual seasons
- Returns:
nodes_data (dict): modified SESMG-nodes data, containing weather data, energy system parameters and timeseries
- variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
Preprocessing/data_preparation/k_means_medoids
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation_algorithms.k_means_medoids.calculate_k_means_clusters(cluster_number: int, weather_data: DataFrame, cluster_criterion: str, period: str) array[source]
Applies the k-means algorithm to a list of day-weather-vectors. Caution: weather data set must be available in hourly resolution!
- Parameters:
cluster_number (int) – Number of k-mean-clusters
weather_data (pandas.DataFrame) – weather_data, the clusters should be applied to
cluster_criterion (str) – weather_parameter/column name which should be applied as cluster criterion
period (str) – defines rather days or weeks were selected
- Returns:
model.labels_ (np.array) - Chronological list, which days of the weather data set belongs to which cluster
- program_files.preprocessing.data_preparation_algorithms.k_means_medoids.calculate_k_medoids_clusters(cluster_number: int, weather_data: DataFrame, cluster_criterion: str, period: str) array[source]
Applies the k-medoids algorithm to a list of day-weather-vectors. Caution: weather data set must be available in hourly resolution!
- Parameters:
cluster_number (int) – Number of k-mean-clusters
weather_data (pandas.DataFrame) – weather_data, the clusters should be applied to
cluster_criterion (str) – weather_parameter/column name which should be applied as cluster criterion
period (str) – defines rather days or weeks were selected
- Returns:
model.labels_ (np.array) - Chronological list, which days of the weather data set belongs to which cluster
- program_files.preprocessing.data_preparation_algorithms.k_means_medoids.k_means_algorithm(cluster_period: int, days_per_cluster: int, criterion: str, nodes_data: dict, period: str) float[source]
identifies k-cluster periods based on the k-means algorithm based on a given criteria. Based on the selected periods, for all timeseries weather data, the respective periods are identified and merged to new shortened timeseries with consecutive time-indices which start with the same start date as the original timeseries. Afterwards, all variable costs are multiplied by the shortening factor (variable cost factor) of the time-series to ensure the same ratio between variable and periodical costs for the energy system optimization model in which the time-series will be applied.
- Parameters:
cluster_period (str) – contains the gui input of the chosen period type (possible entries: days, weeks)
days_per_cluster (int) – contains the gui input of the chosen index (possible entries: 1 - 365)
criterion (str) – criterion chosen for k_mean algorithm
nodes_data (dict) – dictionary containing the excel worksheets from the used model definition workbook
period (str) – defines rather days or weeks were selected
- Raise:
ValueError - Error raised if the chosen period is not supported
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation_algorithms.k_means_medoids.k_medoids_algorithm(cluster_period: int, days_per_cluster: int, criterion: str, nodes_data: dict, period: str) float[source]
identifies k-cluster periods based on the k-medoids algorithm based on a given criteria. Based on the selected periods, for all timeseries weather data, the respective periods are identified and merged to new shortened timeseries with consecutive time-indices which start with the same start date as the original timeseries. Afterwards, all variable costs are multiplied by the shortening factor (variable cost factor) of the time-series to ensure the same ratio between variable and periodical costs for the energy system optimization model in which the time-series will be applied.
- Parameters:
cluster_period (str) – contains the gui input of the chosen period type (possible entries: hours, days, weeks)
days_per_cluster (int) – contains the gui input of the chosen index (possible entries: 1 - 365)
criterion (str) – criterion chosen for k_mean algorithm
nodes_data (dict) – dictionary containing the excel worksheets from the used model definition workbook
period (str) – defines rather days or weeks were selected
- Raise:
ValueError - Error raised if the chosen period is not supported
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation_algorithms.k_means_medoids.k_medoids_timeseries_adaption(nodes_data: dict, clusters: int, cluster_labels, period: str) None[source]
Identifies k-cluster periods from the original timeseries and merges them to a new set of timeseries. A new consecutive time index, starting with the same date as the original dataset is assigned to the merged timeseries.
- Parameters:
nodes_data (dict) – system parameters
clusters (int) – Number of clusters
cluster_labels (np.array) – Chronological list, which days of the weather data set belongs to which cluster
period (str) – defines rather hours, days or weeks were selected
Preprocessing/data_preparation/random_sampling
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation_algorithms.random_sampling.create_new_random_data_set(random_integers: list, data_set: DataFrame, period: str, weatherdata_or_timeseries=True) DataFrame[source]
In this method, the new DataFrames for the subsequent optimization of the energy system are created and returned to the main method.
- Parameters:
random_integers (list) – list of randomly created integers
data_set (pandas.DataFrame) – DataFrame to be prepared for upcoming optimization
period (str) – user chosen period type
weatherdata_or_timeseries (bool) – boolean which defines rather the considered DataFrame is weather data (True) or timeseries (False)
- Returns:
prep_data_set (pandas.DataFrame) - dataframe containing the sampled data dataframe
- program_files.preprocessing.data_preparation_algorithms.random_sampling.random_sampling(nodes_data: dict, period: str, number_of_samples: int) float[source]
In the Random Sampling method, the time series and weather data Dataframes are truncated to the time horizon selected by the user by randomly selecting time steps from the DataFrames.
- Parameters:
nodes_data (dict) – dictionary containing the user’s model definition’s data
period (str) – str containing the slicing period type chosen within the GUI
number_of_samples (int) – amount of samples randomly selected within this method
- Raise:
ValueError - Error raised if the chosen period is not supported
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
Preprocessing/data_preparation/slicing
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.data_preparation_algorithms.slicing.adaption_energy_system_parameter(prep_weather_data: DataFrame, nodes_data: dict, period: str, weather_data: DataFrame) float[source]
Within this method the adaption clusters are calculated and the energy system parameters are adapted afterwards.
- Parameters:
prep_weather_data (pandas.DataFrame) – dataframe containing the sliced weather data data frame
nodes_data (dict) – dictionary containing the model definition’s data
period (str) – str containing the slicing period type chosen within the GUI
weather_data (pandas.DataFrame) – unsliced weather data DataFrame
- Raise:
ValueError - Error raised if the chosen period is not supported
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation_algorithms.slicing.data_set_slicing(n_days: int, data_set: DataFrame, period: str) DataFrame[source]
uses every n-th period of the given data_set and cuts the rest out of the data_set
- Parameters:
n_days (int) – defines which period is chosen
data_set (pandas.core.frame.Dataframe) – data to be sliced
period (str) – defines rather hours, days or weeks were selected
- Returns:
prep_data_set (pandas.DataFrame) - return the sliced pandas.DataFrame
- program_files.preprocessing.data_preparation_algorithms.slicing.data_set_slicing2(n_days: int, data_set: DataFrame, period: str) DataFrame[source]
cuts out every nth period from the given data_set and leaves the remaining periods for further consideration
- Parameters:
n_days (int) – defines which period is sliced
data_set (pandas.core.frame.Dataframe) – data to be sliced
period (str) – defines rather hours, days or weeks were selected
- Returns:
prep_data_set (pandas.DataFrame) - return the sliced pandas.DataFrame
- program_files.preprocessing.data_preparation_algorithms.slicing.timeseries_slicing(n_days: int, nodes_data: dict, period: str) float[source]
uses every n-th period of the given data_set and cuts the rest out of the data_set
- Parameters:
n_days (int) – defines which period is chosen
nodes_data (dict) – data to be sliced
period (str) – defines rather hours, days or weeks were selected
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
- program_files.preprocessing.data_preparation_algorithms.slicing.timeseries_slicing2(n_days: int, nodes_data: dict, period: str) float[source]
cuts out every nth period from the given data_set and leaves the remaining periods for further consideration
- Parameters:
n_days (int) – defines which period is sliced
nodes_data (dict) – data to be sliced
period (str) – defines rather hours, days or weeks were selected
- Returns:
variable_cost_factor (float) - factor that considers the data_preparation_algorithms,
can be used to scale the results up for a year
Preprocessing/import_weather_data
Gregor Becker - gregor.becker@fh-muenster.de
- program_files.preprocessing.import_weather_data.import_open_fred_weather_data(nodes_data: dict, lat: float, lon: float) dict[source]
This method downloads the windpowerlib and the pvlib relevant weather data from the OpenEnergyPlatform and assembles them to the weather data structure of the model definition. The modified model definition (nodes data) is then returned to the main algorithm.
- Parameters:
nodes_data (dict) – dictionary containing the model definition’s data
lat (float) – latitude of the investigated location in WGS84 coordinates
lon (float) – longitude of the investigated location in WGS84 coordinates
- Returns:
nodes_data (dict) - modified model definition data
- program_files.preprocessing.import_weather_data.set_esys_data(nodes_data: dict, location: Point, variables: str) dict[source]
Create the dictionary which is used to download the weather data form the OpenEnergyPlatform Database.
- Parameters:
nodes_data (dict) – dictionary containing the model definition data
location (Point) – shapely Point which represents the considered location
variables (str) – str which differentiates between windpowerlib and pvlib download
- Returns:
- (dict) - dictionary containing the data necessary for the OpenEnergyPlatform Database download
Preprocessing/pareto_optimization
Gregor Becker - gregor.becker@fh-muenster.de Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.pareto_optimization.calc_constraint_limits(result_folders: dict, limits: list) dict[source]
This method reads out the emissions of the monetary-driven minimum as well as those of the emissions-driven minimum, which narrows down the solvable range (interval width) of the model definition. Based on these interval limits, the emission limits for the transformation points (as given in the GUI) are calculated. Here, 0.2 represented a reduction of 20% of the interval width. The optimization will result a result model definition which is limited to 80% (equal or lower) of the emissions calculated for the monetary minimum model definition. Consequently, it is calculated as follows:
![emissions_{mon} =
\mathrm{emissions~of~monetary~driven~minimum}
emissions_{emi} =
\mathrm{emissions~of~emission~driven~minimum}
\mathrm{interval~width} = emission_{mon} - emission_{min}
constraints[x] = emissions_{mon} - limits[x] * \mathrm{interval~width}](_images/math/5004bcf0ea3e09abd5004ab9ced7746628cddb29.png)
The list of limits is then returned as constraints.
- Parameters:
result_folders (dict) – dictionary holding the result paths of monetary and emission minimum
limits (list) – list holding the pareto points to be optimized
- Returns:
constraints (dict) - dict of constraint limits for the transformation points of the pareto optimization
- program_files.preprocessing.pareto_optimization.change_optimization_criterion(nodes_data: dict) None[source]
Swaps the primary optimization criterion (“costs”) with the secondary criterion (“constraint costs”) in the entire model definition. The constraint limit is adjusted.
- Parameters:
nodes_data (dict) – dictionary containing the parameters of the model definition
- program_files.preprocessing.pareto_optimization.create_model_definition_save_folder(model_definition, directory: str, limit='') str[source]
In this method, the folder necessary for a Pareto run (name pattern <model_definition_name>_<constraint_limit>_<timestamp>) is created in the directory. Here, due to the streamlit interface, it must be distinguished whether the model_definitions variable is a str or the object resulting from the GUI. After creation, the path of the newly created folder is returned.
- Parameters:
model_definition (str / streamlit.UploadedFile) – file path of the model definition to be optimized
directory (str) – file path of the main save path
limit (str) – str which is appended on the model name to identify the pareto runs
- Returns:
save_path (str) - path where the optimization results of the pareto point will be stored
- program_files.preprocessing.pareto_optimization.create_transformation_model_definitions(constraints: dict, model_definition, directory: str, limits: list) dict[source]
After the emission limits have been calculated in the calc_constraint_limits method, the transformation model definitions are now created. For this purpose, the model definition entered by the user is imported again and extended by the constraint cost limit. Afterwards it is saved in the Pareto directory (directory) and the path is attached to the dictionary “files”. This dictionary also represents the return value of the method.
- Parameters:
constraints (list) – list containing the maximum emissions caused by the model definitions which will be created within this method
model_definition (str / streamlit.UploadedFile) – file path of the model definition to be optimized
directory (str) – str containing the path of the directory where the created model definitions will be saved
limits (list) – list containing the percentages of reduction defined within the GUI
- Returns:
files (dict) - dictionary holding the combination of limit and path to the new created model definition
- program_files.preprocessing.pareto_optimization.run_pareto(limits: list, model_definition, GUI_main_dict: dict, result_path: str) str[source]
This method represents the main function of Pareto optimization. For this purpose, the model is first run according to the first optimization criterion, then according to the second optimization criterion, after which the semi-optimal intermediate points are determined. Finally, the CSV files are created for further result processing.
- Parameters:
limits (list) – list containing the percentages of reduction defined within the GUI
model_definition (str) – file path of the model definition to be optimized
GUI_main_dict (dict) –
Dictionary which is passed to the method by the GUI and contains the user’s input. The dictionary must contain the following attributes for this method:
pre_modeling
num_threads
time series params
graph state
xlsx select state
console select state
solver select
dh path
cluster dh
pre modeling time series params
investment boundaries
investment boundaries factor
pre model path
result_path (str) – str which contains the result path which is user specific
- Returns:
directory (str) - path where the pareto runs were stored
Preprocessing/pre_model_analysis
Christian Klemm - christian.klemm@fh-muenster.de
- program_files.preprocessing.pre_model_analysis.bus_technical_pre_selection(components_xlsx: DataFrame, result_components: DataFrame) None[source]
deactivates the district heating connection for those busses for which no connection has been carried out during optimization
- Parameters:
components_xlsx (pandas.DataFrame) – DataFrame holding the currently considered sheet of the model definition file
result_components (pandas.DataFrame) – DataFrame holding the currently considered components of the result data components.csv file
- program_files.preprocessing.pre_model_analysis.deactivate_respective_competition_constraints(model_definition_path: str, list_of_deactivated_components: list) DataFrame[source]
identifies which competition constraints contains deactivated components. The respective competition constraints are deactivated in an updated dataframe
- Parameters:
model_definition_path (str) – file path of the pre-model-definition-file which shall be adapted
list_of_deactivated_components (list) – list holding the deactivated components
- Returns:
competition_constraints_xlsx (pandas.DataFrame) - DataFrame holding the updated competition constraints sheet
- program_files.preprocessing.pre_model_analysis.dh_technical_pre_selection(components_xlsx: DataFrame, result_components: DataFrame) None[source]
deactivates district heating investment decisions for which no investments has been carried out
- Parameters:
components_xlsx (pandas.DataFrame) – DataFrame holding the currently considered sheet of the model definition file
result_components (pandas.DataFrame) – DataFrame holding the currently considered components of the result data components.csv file
- program_files.preprocessing.pre_model_analysis.filter_result_component_types(components: DataFrame, component_type: str) DataFrame[source]
returns dataframe containing only one specific component type
- Parameters:
components (pandas.DataFrame) – pandas DataFrame containing the components.csv content
component_type (str) – str defining which component type will be searched for
- Returns:
- (pandas.DataFrame) - return the filtered pandas.DataFrame
- program_files.preprocessing.pre_model_analysis.insulation_technical_pre_selection(components_xlsx: DataFrame, result_components: DataFrame) None[source]
deactivates district heating investment decisions for which no investments has been carried out
- Parameters:
components_xlsx (pandas.DataFrame) – DataFrame holding the currently considered sheet of the model definition file
result_components (pandas.DataFrame) – DataFrame holding the currently considered components of the result data components.csv file
- program_files.preprocessing.pre_model_analysis.technical_pre_selection(components_xlsx: DataFrame, result_components: DataFrame) list[source]
deactivates investment-components for which no investments has been carried out and additionally returns a list of deactivated components
- Parameters:
components_xlsx (pandas.DataFrame) – DataFrame holding the currently considered sheet of the model definition file
result_components (pandas.DataFrame) – DataFrame holding the currently considered components of the result data components.csv file
- Returns:
list_of_deactivated_components (list) - list containing the components which were deactivated within this method
- program_files.preprocessing.pre_model_analysis.tightening_investment_boundaries(components_xlsx: DataFrame, result_components: DataFrame, investment_boundary_factor: int) None[source]
tightens investment boundaries
- Parameters:
components_xlsx (pandas.DataFrame) – DataFrame holding the currently considered sheet of the model definition file
result_components (pandas.DataFrame) – DataFrame holding the currently considered components of the result data components.csv file
investment_boundary_factor (int) – the investment boundaries will be tightened to the respective investment decision of the pre-run multiplied by this factor.
- program_files.preprocessing.pre_model_analysis.update_component_investment_decisions(components: ~pandas.core.frame.DataFrame, model_definition_path: str, model_definition_type_name: str, result_type_name: str, investment_boundary_factor: int, investment_boundaries=True) -> (<class 'pandas.core.frame.DataFrame'>, <class 'list'>)[source]
Adapts investment decision depending on the results of a pre-model and returns new dataset plus list of deactivated components.
- Parameters:
components (pandas.DataFrame) – DataFrame holding the pre-model result data’s components.csv content
model_definition_path (str) – file path of the pre-model-definition-file which shall be adapted
model_definition_type_name (str) – string which defines the model definition’s component type (used to import the correct spreadsheet)
result_type_name (str) – string which defines the result’s component type (used to filter the components.csv file)
investment_boundary_factor (int) – the investment boundaries will be tightened to the respective investment decision of the pre-run multiplied by this factor.
investment_boundaries (bool) – decision whether tightening of the investment boundaries should be carried out
- Returns:
components_xlsx (pandas.DataFrame) - updated DataFrame after the deactivation and investment tightening process
list_of_deactivated_components (list) - list holding the deactivated components
- program_files.preprocessing.pre_model_analysis.update_component_model_definition_sheet(updated_data: DataFrame, model_definition_sheet_name: str, updated_model_definition_path: str) None[source]
updates the original data within the updated model definition sheet
- Parameters:
updated_data (pandas.DataFrame) – DataFrame holding the updated DataFrame resulting from the pre-model algorithm
model_definition_sheet_name (str) – String holding the sheet name to be stored using the pandas ExcelWriter
updated_model_definition_path (str) – path where the update Excel file will be stored
- program_files.preprocessing.pre_model_analysis.update_model_according_pre_model_results(model_definition_path: str, results_components_path: str, updated_model_definition_path: str, investment_boundary_factor: int, investment_boundaries: bool) None[source]
Carries out technical pre-selection and tightens investment boundaries for a model definition, based on a previously performed pre-model.
- Parameters:
model_definition_path (str) – file path of the pre-model-definition-file which shall be adapted
results_components_path (str) – folder path of the pre-model-results on which base the model definition shall be adapted
updated_model_definition_path (str) – file path, where the adapted model definition shall be saved
investment_boundary_factor (int) – the investment boundaries will be tightened to the respective investment decision of the pre-run multiplied by this factor.
investment_boundaries (bool) – decision whether tightening of the investment boundaries should be carried out
Preprocessing/Spreadsheet_Energy_System_Model_Generator
Spreadsheet-Energy-System-Model-Generator.
creates an energy system from a given spreadsheet data file, solves it for the purpose of least cost optimization, and returns the optimal model definition results.
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Oscar Quiroga - oscar.quiroga@fh-muenster.de
- program_files.preprocessing.Spreadsheet_Energy_System_Model_Generator.call_district_heating_creation(nodes_data: dict, nodes: list, busd: dict, district_heating_path: str, result_path: str, cluster_dh: bool) Tuple[dict, list][source]
- Parameters:
nodes_data (dict)
nodes (list)
busd (dict)
district_heating_path (str)
result_path (str)
cluster_dh (bool)
- Returns:
nodes (list) -
busd (dict) -
- program_files.preprocessing.Spreadsheet_Energy_System_Model_Generator.sesmg_main(model_definition_file: str, result_path: str, num_threads: int, criterion_switch: bool, xlsx_results: bool, console_results: bool, timeseries_prep: list, solver: str, cluster_dh, graph=False, district_heating_path=None) None[source]
Main function of the Spreadsheet System Model Generator
- Parameters:
model_definition_file (str ['xlsx']) – The model definition file must contain the components specified above.
result_path (str ['folder']) – path of the folder where the results will be saved
num_threads (int) – number of threads that the method may use
criterion_switch (bool) – boolean which decides rather the first and second optimization criterion will be switched (True) or not (False)
xlsx_results (bool) – boolean which decides rather a flow Spreadsheet will be created for each bus of the energy system after the optimization (True) or not (False)
console_results (bool) – boolean which decides rather the energy system’s results will be printed in the console (True) or not (False)
timeseries_prep (list) – list containing the attributes necessary for timeseries simplifications
solver (str) – str holding the user chosen solver
cluster_dh (bool) – boolean which decides rather the district heating components are clustered street wise (True) or not (False)
graph (bool) – defines if the graph should be created
district_heating_path (str['folder']) – path to the folder where already calculated district heating data is stored
- program_files.preprocessing.Spreadsheet_Energy_System_Model_Generator.sesmg_main_including_premodel(model_definition_file: str, result_path: str, num_threads: int, graph: bool, criterion_switch: bool, xlsx_results: bool, console_results: bool, timeseries_prep: list, solver: str, cluster_dh, pre_model_timeseries_prep: list, investment_boundaries: bool, investment_boundary_factor: int, district_heating_path=None) None[source]
This method solves the specified model definition file is solved twice. First with the pre-model time series preparatory attributes selected by the user. And then (after the pre-modeling algorithm has been performed and the model definition has been reduced to the invested components) the model definition is solved with the main time series preparation algorithms.
- Parameters:
model_definition_file (str ['xlsx']) – The model_definition_file must contain the components specified above.
result_path (str ['folder']) – path of the folder where the results will be saved
num_threads (int) – number of threads that the method may use
criterion_switch (bool) – boolean which decides rather the first and second optimization criterion will be switched (True) or not (False)
xlsx_results (bool) – boolean which decides rather a flow Spreadsheet will be created for each bus of the energy system after the optimization (True) or not (False)
console_results (bool) – boolean which decides rather the energy system’s results will be printed in the console (True) or not (False)
timeseries_prep (list) – list containing the attributes necessary for timeseries simplifications
pre_model_timeseries_prep (list) – list containing the attributes necessary for timeseries simplifications of the first optimization run which is used to reduced the model definition’s amount of components.
investment_boundaries (bool) – Indicates whether “tightening of technical boundaries”, i.e. limiting of investment limits based on the pre-model, is executed.
investment_boundary_factor (int) – Factor by which investment decisions of the pre-model are multiplied to limit the investment limits in the main model.
solver (str) – str holding the user chosen solver
cluster_dh (bool) – boolean which decides rather the district heating components are clustered street wise (True) or not (False)
graph (bool) – defines if the graph should be created
district_heating_path (str['folder']) – path to the folder where already calculated district heating data is stored
Preprocessing/components/Bus
Christian Klemm - christian.klemm@fh-muenster.de GregorBecker - gregor.becker@fh-muenster.de
- program_files.preprocessing.components.Bus.buses(nd_buses: ~pandas.core.frame.DataFrame, timeseries: ~pandas.core.frame.DataFrame, nodes: list) -> (<class 'dict'>, <class 'list'>)[source]
Creates bus objects with the parameters given in ‘nodes_data’ and adds them to the list of components ‘nodes’.
- Parameters:
nd_buses (pandas.DataFrame) – pandas DataFrame, which represents the worksheet “buses” of the previously implemented model definition.
timeseries (pandas.DataFrame) – pandas.DataFrame, which represents the worksheet “timeseries” of the previously implemented model definition.
nodes (list) – list of components created before (can be empty)
- Returns:
busd (dict) - dictionary containing all buses created
nodes (list) - list of all the energy system’s nodes
Preprocessing/components/district_heating
Gregor Becker - gregor.becker@fh-muenster.de
- program_files.preprocessing.components.district_heating.adapt_dhnx_style(thermal_net: ThermalNetwork, cluster_dh: bool) ThermalNetwork[source]
Brings the created pandas Dataframes to the dhnx style.
- Parameters:
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
cluster_dh (bool) – boolean used to distinguish between a clustered heat network or an un-clustered heat network run
- Returns:
thermal_net (ThermalNetwork) - DHNx ThermalNetwork instance after style adaption
- program_files.preprocessing.components.district_heating.add_excess_shortage_to_dh(oemof_opti_model: OemofInvestOptimizationModel, nodes_data: dict, busd: dict, thermal_net: ThermalNetwork, label_5: str) OemofInvestOptimizationModel[source]
With the help of this method, it is possible to map an external heat supply (e.g. from a neighboring heat network) or the export to a neighboring heat network.
- Parameters:
oemof_opti_model (optimization.OemofInvestOptimizationModel) – dh network components
nodes_data (pandas.Dataframe) – Dataframe containing all components data
busd (dict) – dict containing all buses of the energysystem under investigation
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
label_5 (str) – str which defines rather the considered network is an exergy net or an anergy net
- Returns:
oemof_opti_model (optimization.OemofInvestOptimizationModel) - dh network components + excess and shortage bus
- program_files.preprocessing.components.district_heating.clear_thermal_net(thermal_net: ThermalNetwork) ThermalNetwork[source]
Clears the pandas dataframes of the thermal network that might consist of old information.
- Parameters:
thermal_net (dhnx.network.ThermalNetwork) – DHNx ThermalNetwork instance possibly holding information of an older optimization run
- Returns:
thermal_net (dhnx.network.ThermalNetwork) - cleared instance of the DHNx ThermalNetwork
- program_files.preprocessing.components.district_heating.concat_on_thermal_net_components(comp_type: str, new_dict: dict, thermal_net: ThermalNetwork) ThermalNetwork[source]
Concatenates a new row (component) to the thermal network component DataFrames (consumers, producers, forks, etc.) as part of several algorithm steps.
- Parameters:
comp_type (str) – Defines on which thermal net components DataFrame the new dict will be appended.
new_dict (dict) – Holds the information of the new component to be appended on an existing DataFrame.
thermal_net (dhnx.network.ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
- Returns:
thermal_net (dhnx.network.ThermalNetwork) - updated instance of the DHNx ThermalNetwork
- program_files.preprocessing.components.district_heating.create_components(nodes_data: dict, label_5: str, thermal_net: ThermalNetwork) OemofInvestOptimizationModel[source]
Runs dhnx methods for creating thermal network oemof components.
- Parameters:
nodes_data (dict) – dictionary holing model definition sheet information
label_5 (str) – str which defines rather the considered network is an exergy net or an anergy net
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
- Returns:
oemof_opti_model (optimization.OemofInvestOptimizationModel) - model holding dh components
- program_files.preprocessing.components.district_heating.create_connect_dhnx(nodes_data: dict, busd: dict, thermal_net: ~dhnx.network.ThermalNetwork, clustering=False, is_exergy=True) -> (<class 'list'>, <class 'dict'>)[source]
At this point, the preparations of the heating network to use the dhnx package are completed. For this purpose, it is checked whether the given data result in a coherent network, which can be optimized in the following.
- Parameters:
nodes_data (pandas.Dataframe) – Dataframe containing all components data
busd (dict) – dictionary containing model definitions’ buses
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
clustering (bool) – used to define rather the spatial clustering algorithm is used or not
is_exergy (bool) – bool which defines rather the considered network is an exergy net (True) or an anergy net (False)
- Returns:
oemof_opti_model.nodes (list) - energy system nodes of the created thermal network
- program_files.preprocessing.components.district_heating.create_dh_map(thermal_net: ThermalNetwork, result_path: str) None[source]
Within this method the calculated thermal network is plotted as a matplotlib pyplot which can be used for verification of the perpendicular foot print search as well as the imported data.
- Parameters:
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
result_path (str) – path where the resulting map will be stored
- program_files.preprocessing.components.district_heating.district_heating(nodes_data: dict, nodes: list, busd: dict, district_heating_path: str, result_path: str, cluster_dh: bool, is_exergy: bool) -> (<class 'list'>, <class 'dict'>)[source]
The district_heating method represents the main method of heat network creation, it is called by the main algorithm to perform the preparation to use the dhnx components and finally add them to the already existing energy system. It is up to the users to choose whether they want to use spatial clustering or not.
- Parameters:
nodes_data (dict) – dictionary containing the model definitions’ data
nodes (list) – list which contains the already created components
busd (dict) – dictionary containing the model definitions’ buses
district_heating_path (str) – Path to a folder in which the calculated heat network information was stored after a one-time connection point search. Entering this parameter in the GUI shortens the calculation time, because the above mentioned search can then be skipped.
result_path (str) – path where the result will be saved
cluster_dh (bool) – boolean which defines rather the heat network is clustered spatially or not
is_exergy (bool) – bool which defines rather the considered network is an exergy net (True) or an anergy net (False)
- Returns:
nodes (list) - list containing the energy systems’ nodes after the thermal network components were added
- program_files.preprocessing.components.district_heating.filter_pipe_types(pipe_types: DataFrame, label_5: str, pipe_type: str, active=1) DataFrame[source]
Filter pipe types based on given conditions.
- Parameters:
pipe_types (pandas.DataFrame) – DataFrame holding pipe types information.
label_5 (str) – Label for filtering based on anergy/exergy.
pipe_type (str) – Pipe type to filter.
active (int, optional) – Value for the “active” column, defaults to 1.
- Returns:
- (pandas.DataFrame) - Filtered DataFrame.
- program_files.preprocessing.components.district_heating.load_thermal_network_data(thermal_net: ThermalNetwork, path: str, is_exergy: bool) ThermalNetwork[source]
This function takes a ThermalNetwork instance and a path as input. It then reads CSV files for different components (consumers, pipes, producers, forks) from the specified path and attaches the data to the corresponding components in the ThermalNetwork instance. Finally, it returns the modified ThermalNetwork.
- Parameters:
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
path (str) – path where the ThermalNetwork data is stored.
- Returns:
thermal_net (ThermalNetwork) - DHNX ThermalNetwork instance to which the already existing data was attached.
- program_files.preprocessing.components.district_heating.remove_sinks_collect_buses(oemof_opti_model: ~dhnx.optimization.optimization_models.OemofInvestOptimizationModel, busd: dict) -> (<class 'dhnx.optimization.optimization_models.OemofInvestOptimizationModel'>, <class 'dict'>)[source]
Within the dhnx algorithm empty sinks are created, which are removed in this method.
- Parameters:
oemof_opti_model (optimization.OemofInvestOptimizationModel) – parameter holding the district heating optimization model
busd (dict) – dictionary holding the energy system buses
- Returns:
oemof_opti_model (optimization.OemofInvestOptimizationModel) - dh model without unused sinks
busd (dict) - As the busd is always handled as a dictionary of all buses within the SESMG, the buses of the heating network are also added.
- program_files.preprocessing.components.district_heating.save_thermal_network_data(thermal_net: ThermalNetwork, path: str, is_exergy: bool) None[source]
Method to save the calculated thermal network data.
- Parameters:
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance which will be stored within the optimization result folder
path (str) – path where the ThermalNetwork data will be stored.
- program_files.preprocessing.components.district_heating.use_data_of_already_calculated_thermal_network_data(thermal_net: ThermalNetwork, district_heating_path: str, cluster_dh: bool, nodes_data: dict, result_path: str, is_exergy: bool) ThermalNetwork[source]
By this method it is possible to optimize a thermal network without calculating the perpendicular foot points and the heat networks’s components if the user has specified a folder in the GUI where already calculated thermal network data are stored. Nevertheless, a subsequent clustering of the thermal network is possible even if the calculation has already been performed.
- Parameters:
thermal_net (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
district_heating_path (str) – string of the path where the already calculated thermal network data is stored
cluster_dh (bool) – boolean which decides rather the thermal network will be clustered or not
nodes_data (dict) – dictionary containing the model definitions’ data
result_path (str) – path where the optimization results as well as the district heating calculations will be stored
- Returns:
thermal_net (ThermalNetwork) - Thermal network holding the networks’ components which were loaded from the users input path in the GUI
Preprocessing/components/district_heating_calculations
Gregor Becker - gregor.becker@fh-muenster.de
- program_files.preprocessing.components.district_heating_calculations.calc_heat_pipe_attributes(oemof_opti_model: OemofInvestOptimizationModel, pipe_types: DataFrame) OemofInvestOptimizationModel[source]
In this method, the DHNx components, which were created for a purely monetary consideration of the heat network, are extended by the emissions approach common in the SESMG. For this purpose, the length of the component is determined based on the component already created, and the emissions caused are then calculated based on this length. These are then assigned to the investment attribute of the respective pipe section as an emission value. Finally, the extended model is returned.
- Parameters:
oemof_opti_model (optimization.OemofInvestOptimizationModel) – DHNx Model containing the thermal network components
pipe_types (pandas.DataFrame) – DataFrame containing the model definition’s pipe types sheet
- Returns:
oemof_opti_model (optimization.OemofInvestOptimizationModel) - DHNx Model which was extended by the SESMG common emission approach
- program_files.preprocessing.components.district_heating_calculations.calc_perpendicular_distance_line_point(p1: array, p2: array, p3: array, converted=False) list[source]
Determination of the perpendicular foot point as well as the distance between point and straight line. The points consist an array e.g [51.5553878, 7.21026385] which northern latitude and eastern longitude.
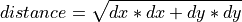
where
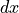 and
and 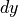 are defined as:
are defined as: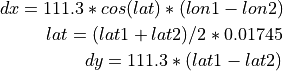
lat1, lat2, lon1, lon2: northern latitude, eastern longitude in degree
- Parameters:
p1 (numpy.array) – Starting point of the road section
p2 (numpy.array) – Ending point of the road section
p3 (numpy.array) – point of the building under consideration
converted (bool) – defines rather the points are given in EPSG 31466 or not
- Returns:
- (list) - list containing the perpendicular foot point longitude [0] and longitude [1] the distance to the distance to the investigated point as well as it’s t value which is the relative position on the street section
- program_files.preprocessing.components.district_heating_calculations.calc_street_lengths(connection_points: list) list[source]
Calculates the distances between the points of a given street given as connection_points.
- Parameters:
connection_points (list) – list of connection_points on the given street
- Returns:
ordered_road_section_points (list) - list containing all points of a certain street in an ordered sequence
- program_files.preprocessing.components.district_heating_calculations.convert_street_sec_coordinates(street_sec: DataFrame) DataFrame[source]
Convert street sections Dataframe to Gaussian Kruger (GK) to reduce redundancy.
- Parameters:
street_sec (pandas.DataFrame) – Dataframe holding start and end points of the streets under investigation
- Returns:
street_sec (pandas.DataFrame) - holding converted points
- program_files.preprocessing.components.district_heating_calculations.get_nearest_perp_foot_point(building: Series, streets: DataFrame, index: int, building_type: str) list[source]
Uses the calc_perpendicular_distance_line_point method and finds the shortest distance to a road from its results.
- Parameters:
building (pandas.Series) – coordinates of the building under investigation
streets (pandas.Dataframe) – Dataframe holding all street section of the territory under investigation
index (int) – integer used for unique indexing of the foot points.
building_type (str) – specifies building type
- Returns:
foot_point (list) - list containing information of the perpendicular foot point
Preprocessing/components/district_heating_clustering
Gregor Becker - gregor.becker@fh-muenster.de
- program_files.preprocessing.components.district_heating_clustering.clear_thermal_network_dataframes(thermal_network: ThermalNetwork) ThermalNetwork[source]
Remove the not longer used pipes and forks of the unclustered thermal network to create the new ones afterwards.
- Parameters:
thermal_network (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
- Returns:
thermal_network (ThermalNetwork) - DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system. Within this method the not longer used forks and pipes were deleted.
- program_files.preprocessing.components.district_heating_clustering.clustering_dh_network(nodes_data: dict, thermal_network: ThermalNetwork) ThermalNetwork[source]
Using this method, a spatial clustering of the thermal network is carried out based on the road sections entered by the user.
- Parameters:
thermal_network (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
nodes_data (dict) – dictionary holding the users model definition’s data
- Returns:
thermal_network (ThermalNetwork) - DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
- program_files.preprocessing.components.district_heating_clustering.connect_clustered_dh_to_system(oemof_opti_model, busd: dict, thermal_network: ThermalNetwork, nodes_data: dict) OemofInvestOptimizationModel[source]
Method which creates links to connect the model definition based created sinks to the thermal network components created before.
Note
The calculation of the periodical cost of the clustered heat pipeline is based on the linearization of the heatpipe type due to the iterative approach see parameters sheet.
a distinction between exergy and anergy has not been implemented yet
- Parameters:
oemof_opti_model – Oemof model holing thermal network
busd (dict) – dictionary containing model definition buses
thermal_network (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
nodes_data (dict) – dictionary holding the users model definition’s data
- Returns:
oemof_opti_model (optimization.OemofInvestOptimizationModel) - model holding dh components
- program_files.preprocessing.components.district_heating_clustering.get_forks_street_section_wise(nodes_data: dict, forks: DataFrame) dict[source]
Within this method all perpendicular foot points within one street section are collected to create the clustered foot point later on.
- Parameters:
nodes_data (dict) – dictionary holding the users model definition’s data
forks (pandas.DataFrame) – DataFrame holding the unclustered thermal networks’ forks
- Returns:
forks_street (dict) - dict holding the combination of the street label and a list of it’s connected forks
- program_files.preprocessing.components.district_heating_clustering.get_pipe_lengths_street_section_wise(forks_street: dict, thermal_network: ~dhnx.network.ThermalNetwork, pipes: ~pandas.core.frame.DataFrame) -> (<class 'dhnx.network.ThermalNetwork'>, <class 'dict'>)[source]
Within this method all pipe lengths connected to an investigated street section are collected. The not longer used pipes are deleted afterwards.
- Parameters:
forks_street (dict) – dict holding the combination of the street label and a list of it’s connected forks
thermal_network (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
pipes (pandas.DataFrame) – DataFrame holding the unclustered thermal networks’ pipes
- Returns:
thermal_network (ThermalNetwork) - DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system. Within this method the not longer used pipes were deleted.
streets_pipe_length - dictionary holding the combination of a street section’s label and a list of all pipes that were connected to the investigated street section
- program_files.preprocessing.components.district_heating_clustering.get_street_sections_consumers_information(streets_pipe_length: dict, thermal_network: ~dhnx.network.ThermalNetwork, consumers: ~pandas.core.frame.DataFrame) -> (<class 'dhnx.network.ThermalNetwork'>, <class 'dict'>)[source]
Within this method all consumer information of consumers connected to an investigated street section are collected. The not longer used consumers are deleted afterwards.
- Parameters:
streets_pipe_length (dict) – dictionary holding the combination of a street section’s label and a list of all pipes that were connected to the investigated street section
thermal_network (ThermalNetwork) – DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system.
consumers (pandas.DataFrame) – DataFrame holding the unclustered thermal networks’ consumers
- Returns:
thermal_network (ThermalNetwork) - DHNx ThermalNetwork instance used to create the components of the thermal network for the energy system. Within this method the not longer used consumers were deleted.
streets_consumer - dictionary holding the combination of a street section’s label and a list of consumer information of all consumers that were connected to the investigated street section
Preprocessing/components/Link
Christian Klemm - christian.klemm@fh-muenster.de
- class program_files.preprocessing.components.Link.Links(nodes_data: dict, nodes: list, busd: dict)[source]
Bases:
objectCreates link objects as defined in ‘nodes_data’ and adds them to the list of components ‘nodes’.
- Parameters:
nodes_data (dict) –
dictionary containing data from excel model definition file. The following data have to be provided:
active
label
(un)directed
efficiency
bus1
bus2
periodical costs
periodical constraint costs
variable output costs
variable output constraint costs
non-convex investment
fix investment costs
fix investment constraint costs
min. investment capacity
max. investment capacity
existing capacity
nodes (list) – list of components created before (can be empty)
busd (dict) – dictionary containing the buses of the energy system
- static get_flow(link: Series, nodes_data: dict) Flow[source]
The parameterization of the output flow of the link component has been outsourced to this static method.
- Parameters:
link (pandas.Series) – nodes data row of the link in creation
nodes_data (dict) – dict containing data from the excel model definition given by the user
- Returns:
- (oemof.solph.Flow) - oemof Flow object with the output’s parameter given in the link parameter
Preprocessing/components/Sink
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de
- class program_files.preprocessing.components.Sink.Sinks(nodes_data: dict, busd: dict, nodes: list)[source]
Bases:
objectWithin this class the ‘nodes_data’ given sinks are created. Therefore there is a differentiation between four types of sink objects to be created:
unfixed: a sink with flexible time series
timeseries: a sink with predefined time series
SLP: a VDEW standard load profile component
richardson: a component with stochastically generated time series
- Parameters:
nodes_data (dict) –
dictionary containing parameters of sinks to be created. The following data have to be provided:
label
sector
active
fixed
input
load profile
nominal value
annual demand
occupants (only needed for the Richardson sinks)
building class
wind class
busd (dict) – dictionary containing the buses of the energy system
nodes (list) – list of components created before (can be empty)
- calc_insulation_parameter(ins: ~pandas.core.series.Series) -> (<class 'float'>, <class 'float'>, <class 'list'>)[source]
Calculation of insulation measures for the considered sink
Temperature difference is calculated according to:
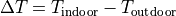
is only calculated for the time steps in which the temperature falls below the heating limit temperature.
U-value difference is calculated according to:
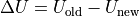
Calculation of the capacity that can be saved according to:
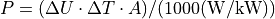
- Params:
ins (pandas.Series) - considered insulation row
- Returns:
ep_costs (float) - periodical costs of the considered insulation
ep_constr_costs (float) - periodical constraint costs of the considered insulation
temp (list) - list containing the capacity to be saved for each time step
- create_insulation_source(label: str, bus: str, args: dict) None[source]
Create insulation sources for the considered sink “label”.
- Parameters:
label (str) – Label of the considered sink.
bus (str) – Bus associated with the sink (input).
args (dict) – Dictionary containing additional arguments.
- create_sink(sink: Series, nominal_value=None, load_profile=None, args=None) None[source]
Creates an oemof sink with fixed or unfixed timeseries.
- Parameters:
sink (pandas.Series) – pandas.Series containing information for the creation of an oemof sink.
nominal_value (float) – Float containing the nominal demand of the sink to be created. Only used if the args parameter remains empty.
load_profile (pandas.Series) – load Profile contains the time series of the sink to be created. This is used for the fixed (fix) or the maximum (unfix) time series depending on the sink type. Only used if the args parameter remains empty.
args (dict) – dictionary rather containing the ‘fix-attribute’ or the ‘min-’ and ‘max-attribute’ of a sink
- richardson_sink(sink: Series) None[source]
Creates a sink with stochastically generated input, using richardson.py. Used for the modelling of residential electricity demands. In this context the method uses the create_sink method.
- Parameters:
sink (pandas.Series) – dictionary containing all information for the creation of an oemof sink.
- slp_sink(sink: Series) None[source]
Creates a sink with a residential or commercial SLP time series.
Creates a sink with inputs according to VDEW standard load profiles, using oemof’s demandlib. Used for the modelling of residential or commercial electricity demand. In this context the method uses the create_sink method.
- Parameters:
sink (pandas.Series) –
dictionary containing all information for the creation of an oemof sink. At least the following key-value-pairs have to be included:
label
load profile
annual demand
building class
wind class
- timeseries_sink(sink: Series) None[source]
Creates a sink object with a fixed input. The input must be given as a time series in the model definition file. In this context the method uses the create_sink method.
When creating a time series sink, a distinction is made between unfixed and fixed operation in the case of unfixed operation, the design range must be limited by a lower and upper limiting time series (.min and .max) in the case of a fixed time series sink, only one load profile (.fix) is required.
- Parameters:
sink (pandas.Series) – dictionary containing all information for the creation of an oemof sink
Preprocessing/components/Source
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Yannick Wittor - yw090223@fh-muenster.de
- class program_files.preprocessing.components.Source.Sources(nodes_data: dict, nodes: list, busd: dict)[source]
Bases:
objectCreates an oemof source with fixed or unfixed timeseries.
There are six options for labeling source objects to be created:
‘commodity’: a source with flexible time series
‘timeseries’: a source with predefined time series
‘photovoltaic’: a photovoltaic component
‘wind power’: a wind power component
‘solar thermal components’: a solar thermal or concentrated solar power component
- Parameters:
nodes_data (dict) –
dictionary containing parameters of sources to be created. The following data have to be provided:
label
active
fixed
output
technology
input
variable costs
existing capacity
min. investment capacity
max. investment capacity
periodical costs
non-convex investment
fix investment cost
fix investment constraint costs
variable constraint costs
periodical constraint costs
Turbine Model (Windpower ONLY)
Hub Height (Windpower ONLY)
Modul Model (PV ONLY)
Inverter Model (PV ONLY)
Azimuth
Surface Tilt
Albedo
Altitude (PV ONLY)
Latitude
Longitude
ETA 0
A1
A2
C1
C2
Temperature Inlet
Temperature Difference
Conversion Factor
Peripheral Losses
Cleanliness
busd (dict) – dictionary containing the buses of the energy system
nodes (list) – list of components created before (can be empty)
- change_inverter_limits(inv_params: Series, p_stc: float, dc_ac_ratio: float)[source]
Changes inverter simulation limits to focus solely on conversion efficiency.
Scales the inverter’s capacity based on the DC system size and DC/AC ratio, and removes lower operational thresholds to prevent artificial clipping or shutdowns.
This normalization is critical to allow arbitrary inverter models to be paired with any DC system size (e.g., simulating a single 400W module). Without removing thresholds like Pso, large commercial inverters would never start operating in a small-scale or single-module simulation because their physical startup thresholds often require several kilowatts.
- Parameters:
inv_params (pandas.Series) – Series containing inverter parameters.
p_stc (float) – DC power at STC (Standard Test Conditions) in Watts.
dc_ac_ratio (float) – Scaling factor for AC/DC power ratio.
- Returns:
Modified inverter parameters.
- Return type:
pandas.Series
- commodity_source(source: Series) None[source]
Creates an oemof source object with flexible time series (no maximum or minimum) with the use of the create_source method.
- Parameters:
source (pandas.Series) – Series containing all information for the creation of an oemof source. At least the following key-value-pairs have to be included: - ‘label’
- create_feedin_source(feedin: Series, source: Series, output=None, variable_costs=None) None[source]
In this method, the parameterization of the output flow for sources has been outsourced, since it is not source type dependent.
- Parameters:
feedin (pandas.Series) – time series holding the sources relative output capacity
source (pandas.Series) –
Series containing all information for the creation of an oemof source. At least the following key-value-pairs have to be included:
fixed
label
output
output (oemof.solph.Bus) – variable that contains the output of the source if it differs from the value entered in the spreadsheet.
variable_costs (list) – variable which contains the variable output cost of the source if it differs from the value entered in the spreadsheet.
- create_source(source: Series, timeseries_args: dict, output=None, variable_costs_list=None) None[source]
Creates an oemof source with fixed or unfixed timeseries
- Parameters:
source (pandas.Series) –
Series containing all information for the creation of an oemof source. At least the following key-value-pairs have to be included:
label
output
periodical costs
periodical constraint costs
min. investment capacity
max. investment capacity
existing capacity
non-convex investment
fix investment costs
fix investment constraint costs
variable costs
variable constraint costs
timeseries_args (dict) – dictionary rather containing the ‘fix-attribute’ or the ‘min-’ and ‘max-attribute’ of a source
output (Bus) – defines the oemof output bus
variable_costs_list (list) – list containing components variable costs if they differ from the spreadsheets entries
- infer_cec_params(source: Series) Series[source]
Calculates CEC 6-parameter set from datasheet specifications.
Uses pvlib.ivtools.sdm.fit_cec_sam() (Dobos 2012) to estimate parameters for the single diode model. Requires NREL-PySAM to be installed.
- Note on Units:
alpha_sc: Must be [A/°C]. If datasheet gives [%/°C], convert via: alpha_sc_% / 100 * i_sc
beta_voc: Must be [V/°C]. If datasheet gives [%/°C], convert via: beta_voc_% / 100 * v_oc
gamma_pmp: Remains [%/°C] (e.g. -0.35), no conversion needed.
- Parameters:
source (pandas.Series) – Series containing datasheet values: - celltype: e.g., ‘monoSi’ - v_mp: Voltage at maximum power point [V] - i_mp: Current at maximum power point [A] - v_oc: Open circuit voltage [V] - i_sc: Short circuit current [A] - alpha_sc: Temp. coefficient of i_sc [A/°C] - beta_voc: Temp. coefficient of v_oc [V/°C] - gamma_pmp: Temp. coefficient of p_mp [%/°C] - cells_in_series: Number of cells in series - STC: Nominal power at STC [W]
- Returns:
Series with parameters for PVSystem/ModelChain
- Return type:
pandas.Series
- pv_source(source: Series) None[source]
Creates an oemof photovoltaic source object.
Simulates the yield of a photovoltaic system using pvlib and creates a source object with the yield as time series and the use of the create_source method. Supports both database-lookup and datasheet-inference for module parameters.
- Parameters:
source (pandas.Series) –
Series containing all information for the creation of an oemof source. At least the following key-value-pairs have to be included:
label
fixed
technology: ‘photovoltaic’ or ‘photovoltaic_datasheet’
azimuth
surface tilt
modul model
albedo
latitude
longitude
altitude
inverter_power
inverter_eta
- solar_heat_source(source: Series) None[source]
Creates a solar thermal collector source object.
Calculates the yield of a solar thermal flat plate collector or a concentrated solar power collector as time series by using oemof.thermal and the create_source method.
The following key-value-pairs have to be included in the keyword arguments:
- Parameters:
source (pandas.Series) –
has to contain the following keyword arguments:
input
- technology:
solar_thermal_flat_plate or
concentrated_solar_power
Latitude
Longitude
Surface Tilt
Azimuth
Cleanliness
ETA 0
A1
A2
C1
C2
Temperature Inlet
Temperature Difference
Conversion Factor
Peripheral Losses
- timeseries_source(source: Series) None[source]
Creates an oemof source object from a pre-defined timeseries with the use of the create_source method. A distinction is made here between a fixed source, which has only one time series for generation, and an unfixed source, which is limited by a lower and an upper time series.
- Parameters:
source (pandas.Series) –
Series containing all information for the creation of an oemof source. At least the following key-value-pairs have to be included:
label
output
periodical costs
periodical constraint costs
min. investment capacity
max. investment capacity
existing capacity
non-convex investment
fix investment costs
fix investment constraint costs
variable costs
variable constraint costs
- windpower_source(source: Series) None[source]
Creates an oemof windpower source object.
Simulates the yield of a windturbine using feedinlib and creates a source object with the yield as time series and the use of the create_source method.
- Parameters:
source (pandas.Series) –
Series containing all information for the creation of an oemof source. At least the following key-value-pairs have to be included:
label
fixed
Turbine Model (Windpower ONLY)
Hub Height (Windpower ONLY)
Preprocessing/components/Storage
Christian Klemm - christian.klemm@fh-muenster.de Yannick Wittor - yw090223@fh-muenster.de
- class program_files.preprocessing.components.Storage.Storages(nodes_data: dict, nodes: list, busd: dict)[source]
Bases:
objectCreates oemof storage objects as defined in ‘nodes_data’ and adds them to the list of components ‘nodes’.
- Parameters:
nodes_data (dict) –
dictionary containing parameters of the storages to be created. The following data have to be provided:
label
active
input
output
storage type
existing capacity
min. investment capacity
max.investment capacity
non-convex investments
fix investment costs
fix investment constraint costs
input/capacity ratio
output/capacity ratio
efficiency inflow
efficiency outflow
initial capacity
capacity min
capacity max
periodical costs
periodical constraint costs
variable input costs
variable input constraint costs
variable output costs
variable output constraint costs
capacity loss (Generic)
diameter (Stratified)
temperature high (Stratified)
temperature low (Stratified)
U value (Stratified)
busd (dict) – dictionary containing the buses of the energy system
nodes (list) – list of components created before (can be empty)
- create_storage(storage: Series, loss_rate: Series, storage_levels: list, fixed_losses: list) None[source]
Within this method the previously prepared storage parameters are used to create an oemof storage object with the given parameters and add it to the class intern list nodes which is returned to the main algorithm at the end.
- Parameters:
storage (pandas.Series) –
Series containing all information for the creation of an oemof storage. At least the following key-value-pairs have to be included:
label
active
input
output
storage type
existing capacity
min. investment capacity
max.investment capacity
non-convex investments
fix investment costs
fix investment constraint costs
input/capacity ratio
output/capacity ratio
efficiency inflow
efficiency outflow
initial capacity
capacity min
capacity max
periodical costs
periodical constraint costs
variable input costs
variable input constraint costs
variable output costs
variable output constraint costs
loss_rate (pandas.Series) – time series holding the loss coefficient foreach time step
storage_levels (list) – list containing the minimum and maximum storage level
fixed_losses (list) – list containing the minimum and maximum fixed losses (independent of the mode of operation)
- generic_storage(storage: Series) None[source]
Creates a generic storage object with the parameters given in ‘nodes_data’ and adds it to the list of components ‘nodes’.
- Parameters:
storage (pandas.Series) – Series containing all information for the creation of an oemof storage.
- stratified_thermal_storage(storage: Series) None[source]
Creates a stratified thermal storage object with the parameters given in ‘nodes_data’ and adds it to the list of components ‘nodes’.
- Parameters:
storage (pandas.Series) –
Series which has to contain the following keyword arguments:
Standard information on Storages
storage type: Stratified
diameter
temperature high
temperature low
U value /(W/(sqm*K))
Preprocessing/components/Transformer
Christian Klemm - christian.klemm@fh-muenster.de Janik Budde - Janik.Budde@fh-muenster.de Yannick Wittor - yw090223@fh-muenster.de
- class program_files.preprocessing.components.Transformer.Transformers(nodes_data: dict, nodes: list, busd: dict)[source]
Bases:
objectCreates transformer objects as defined in ‘nodes_data’ and adds them to the list of components ‘nodes’.
- Parameters:
nodes_data (dict) – A dictionary containing data from the excel model definition file.
nodes (list) – list of components created before (can be empty)
busd (dict) – dictionary containing the buses of the energy system
- absorption_heat_transformer(transformer: Series) None[source]
Creates an absorption heat transformer object with the parameters given in ‘nodes_data’ and adds it to the list of components ‘nodes’
- Parameters:
transformer (pandas.Series) –
Series containing all information for the creation of an oemof transformer. At least the following key-value-pairs have to be included:
label
variable input costs
variable input constraint costs
variable output costs
variable output constraint costs
periodical costs
periodical constraint costs
non-convex investment
fix investment costs
fix investment constraint costs
efficiency
min. investment capacity
max. investment capacity
existing capacity
name: name refers to models of absorption heat transformers with different equation parameters. See documentation for possible inputs.
temperature high
temperature low
electrical input conversion factor
recooling temperature difference
- compression_heat_transformer(transformer: Series) None[source]
Creates a Compression Heat Pump or Compression Chiller by using oemof.thermal and adds it to the list of components ‘nodes’.
- Parameters:
transformer (pd.Series) –
Series containing all information for the creation of an oemof transformer. At least the following key-value-pairs have to be included:
label
variable input costs
variable input constraint costs
variable output costs
variable output constraint costs
min. investment capacity
max. investment capacity
existing capacity
efficiency
periodical costs
periodical constraint costs
non-convex investment
fix investment costs
fix investment constraint costs
mode:
’heat_pump’ or
’chiller’
heat source
temperature high
temperature low
quality grade
area
length of the geoth. probe
heat extraction
min. borehole area
temp. threshold icing
factor icing
- Raises:
SystemError – chosen heat source not defined
- create_abs_comp_bus(transformer: Series) str[source]
create absorption chiller and compression heat transformer’s intern bus
- Parameters:
transformer (pandas.Series) –
Series containing all information for the creation of an oemof transformer. At least the following key-value-pairs have to be included:
label
mode
- Returns:
temp (str) - mode specific bus label ending
- create_transformer(transformer: Series, inputs: dict, conversion_factors: dict, outputs: dict) None[source]
Within this method the parameterized transformer (inputs, outputs and conversion factors already created) is added to the class intern list of nodes and returned to the main algorithm at the end.
- Parameters:
transformer (pandas.Series) –
Series containing the transformer’s parameter. Series has to contain at least the following key-value pairs:
label
inputs (dict) – dictionary holding the transformer’s input flows
outputs (dict) – dictionary holding the transformer’s output flows
conversion_factors (dict) – dictionary holding the transformer’s input and output conversion factors
- generic_transformer(transformer: Series, two_input=False) None[source]
Creates a generic transformer with the parameters given in ‘nodes_data’ and adds it to the list of components ‘nodes’.
- Parameters:
transformer (pandas.Series) –
Series containing all information for the creation of an oemof transformer. At least the following key-value-pairs have to be included:
label
input
input2
output
output2
efficiency
efficiency2
input2 / input
variable input costs
variable input constraint costs
variable input costs 2
variable input constraint costs 2
variable output costs
variable output constraint costs
variable output costs 2
variable output constraint costs 2
periodical costs
periodical constraint costs
min. investment capacity
max. investment capacity
existing capacity
non-convex investment
fix investment costs
fix investment constraint costs
two_input (bool) – boolean which is used to differentiate between the creation process of an one or a two input transformer
- genericchp_transformer(transformer: Series) None[source]
Creates a generic chp transformer with the parameters given in ‘nodes_data’ and adds it to the list of components ‘nodes’.
WARNING: Currently the GenericCHP component can only be used for the purpose of simulation. The solver is not able to dimension the components capacity. Since there is no investment decision no periodical costs apply.
- Parameters:
transformer (pandas.Series) –
Series containing all information for the creation of an oemof transformer. At least the following key-value-pairs have to be included:
label
input
output
output2
variable input costs
variable input constraint costs
variable output costs
variable output constraint costs
variable output costs 2
variable output constraint costs 2
min. share of flue gass loss
max. share of flue gass loss
min. electric power
max. electric power
min. electric efficiency
max. electric efficiency
minmal thermal output power
elec. power loss index
back pressure
- get_primary_output_data(transformer: Series, max_invest=None) dict[source]
Within this method the output flow data of the currently considered transformer is parameterized and returned to the transformer creation method. This method results from the equality of output parametrization of nearly each transformer.
- Parameters:
transformer (pandas.Series) –
Series containing the transformer’s parameter. Series has to contain at least the following key-value pairs:
min. investment capacity
max. investment capacity
periodical costs
periodical constraint costs
existing capacity
non-convex investment
fix investment costs
fix investment constraint costs
variable output costs
variable output constraint costs
max_invest (float) – float value, which allows to reduce the maximum capacity value for ground source heat pump to the heat pump extraction capacity from the ground, since this is usually the factor limiting the capacity.
- Returns:
- (dict) - dictionary holding the primary output of the considered transformer
- get_secondary_output_data(transformer: Series) dict[source]
Generates and returns data for the secondary output of a transformer.
- Parameters:
transformer (pandas.Series) – A pandas Series containing information about the transformer.
- Returns:
- (dict) - A dictionary containing data for the secondary output.
Processing
Processing/optimize_model
Gregor Becker - gregor.becker@fh-muenster.de Christian Klemm - christian.klemm@fh-muenster.de
- program_files.processing.optimize_model.competition_constraint(om: Model, comp_constraints: DataFrame, energy_system: EnergySystem) Model[source]
The outflow_competition method is used to optimise the sum of the outflows of two given components multiplied by two different factors (e.g. the space required for a kW) against a given limit.
- Parameters:
om (oemof.solph.Model) – oemof solph model to which the constraints will be added
comp_constraints (pandas.DataFrame) – pandas dataframe of the competition constraint sheet
energy_system (oemof.solph.energy_system) – the oemof created energy_system containing all created components
- Returns:
om (oemof.solph.Model) - oemof solph Model within the newly added competition constraints
- program_files.processing.optimize_model.constraint_optimization_against_two_values(om: Model, limit: float, storages=False) Model[source]
Function for optimization against two parameters (e.g. monetary, emissions)
- Parameters:
om (oemof.solph.Model) – oemof solph model to which the constraints will be added
limit (int) – maximum value for the second parameter for the whole energysystem
storages (bool) – boolean indicating whether or not the energy system has a storage as an investment alternative.
- Returns:
om (oemof.solph.Model) - oemof solph Model within the added constraints
- program_files.processing.optimize_model.constraint_optimization_of_criterion_adherence_to_a_minval(om: Model, limit: float) Model[source]
Using this method, the solver can be forced to reduce the final energy demand by insulation measures. In this case, all flows from the insulation investments are summed up and the solver is forced to at least reach the value limit.
- Parameters:
om (oemof.solph.Model) – oemof solph model to which the constraints will be added
limit (float) – Value by which the solver must reduce the final energy demand by investing in insulation measures.
- Returns:
om (oemof.solph.Model) - oemof solph Model within the newly added constraints
- program_files.processing.optimize_model.least_cost_model(energy_system: EnergySystem, num_threads: int, nodes_data: dict, busd: dict, solver: str) Model[source]
Solves a given energy system for least costs and returns the optimized energy system.
- Parameters:
energy_system (oemof.solph.Energysystem) – energy system consisting a number of components
num_threads (int) – number of threads the solver is allowed to use
nodes_data (dict) – dictionary containing all components information out of the excel spreadsheet
busd (dict) – dictionary containing the buses of the energysystem
solver (str) – str holding the user chosen solver label
- Returns:
om (oemof.solph.Model) - solved oemof model
Postprocessing
Postprocessing/create_results
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Oscar Quiroga - oscar.quiroga@fh-muenster.de
- class program_files.postprocessing.create_results.Results(nodes_data: dict, optimization_model: Model, energy_system: EnergySystem, result_path: str, variable_cost_factor: float, console_log: bool, cluster_dh: bool)[source]
Bases:
objectReturns a list of all defined components with the following information:
component
information
sinks
Total Energy Demand
sources
Total Energy Input, Max. Capacity, Variable Costs, Periodical Costs
transformers
Total Energy Output, Max. Capacity, Variable Costs, Investment Capacity, Periodical Costs
storages
Energy Output, Energy Input, Max. Capacity, Total variable costs, Investment Capacity, Periodical Costs
links
Total Energy Output
Furthermore, a list of recommended investments is printed.
The algorithm uses the following steps:
logging the component type for example “sinks”
creating pandas dataframe out of the results of the optimization consisting of every single flow in/out a component
calculating the investment and the costs regarding the flows
adding the component to the list of components (loc) which is part of the plotly dash and is the content of components.csv
- Parameters:
nodes_data (dict) – dictionary containing data from excel model definition file
optimization_model (oemof.solph.Model) – optimized energy system
energy_system (oemof.solph.Energysystem) – original (unoptimized) energy system
result_path (str) – Path where the results are saved.
variable_cost_factor (float) – factor that considers the data_preparation_algorithms, can be used to scale the results up for a year
console_log (bool) – boolean which decides rather the results will be logged in the console or not
cluster_dh (bool) – boolean which decides rather the thermal network was spatially clustered or not
- program_files.postprocessing.create_results.charts(nodes_data: dict, optimization_model: Model, energy_system: EnergySystem) None[source]
Plots model results in- and outgoing flows of every bus of a given, optimized energy system (based on matplotlib)
- Parameters:
nodes_data (dict) – dictionary containing data from excel model definition file
optimization_model (oemof.solph.Model) – optimized energy system
energy_system (oemof.solph.Energysystem) – original (unoptimized) energy system
- program_files.postprocessing.create_results.xlsx(nodes_data: dict, optimization_model: Model, filepath: str) None[source]
Returns model results as xlsx-files. Saves the in- and outgoing flows of every bus of a given, optimized energy system as .xlsx file
- Parameters:
nodes_data (dict) – dictionary containing data from excel model definition file
optimization_model (oemof.solph.model) – optimized energy system
filepath (str) – path, where the results will be stored
Postprocessing/create_results_collecting_data
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de
- program_files.postprocessing.create_results_collecting_data.calc_periodical_costs(node, investment: float, comp_type: str, cost_type: str) float[source]
method to calculate the component’s periodical costs for the first optimization criterion (cost_type = costs) or the second optimization criterion (cost_type = emissions)
- Parameters:
node (different oemof solph components) – component under investigation
investment (float) – float containing the investment value of the considered component (node)
comp_type (str) – str holding the component’s type
cost_type (str) – str that makes the distinction between a monetary or emissions calculation
- Returns:
- (float) - float holding the calculated periodical costs or emissions
- program_files.postprocessing.create_results_collecting_data.calc_variable_costs(node, comp_dict: list, attr: str) float[source]
method to calculate the component’s variable costs for the first optimization criterion (attr = variable costs) or the second optimization criterion (attr = emission factor)
- Parameters:
node (different oemof solph components) – component under investigation
comp_dict (list) – list holding the energy system component’s information as specified in the main method collect_data
attr (str) – str defining the cost factor’s name to get the attribute from the component’s data
- Returns:
costs (float) - float holding the calculated variable costs or emissions
- program_files.postprocessing.create_results_collecting_data.change_heatpipelines_label(comp_label: str, result_path: str) str[source]
method used to make the heatpipeline labels easier to read
- Parameters:
comp_label (str) – energy system intern label for the specific heatpipeline part
result_path (str) – str holding the algorithms result path used for the energy system’s pipes data
- Returns:
loc_label (str) - string containig the easy readable label for the list of components (loc)
- program_files.postprocessing.create_results_collecting_data.check_for_link_storage(node, nodes_data: DataFrame) str[source]
since there are component specific decisions (e.g. capacity) especially for storages and links the component type of the investigated component (node) is collected within this method
- Parameters:
node (different oemof solph components) – component under investigation
nodes_data (pandas.DataFrame) – Dataframe containing all energy system components data from the input Excel File
- Returns:
return_str (str) - containing the component type e.g. storage or link
- program_files.postprocessing.create_results_collecting_data.collect_data(nodes_data: dict, results: dict, esys: EnergySystem, result_path: str, variable_cost_factor: float) Tuple[dict, float, float][source]
main method of the algorithm used to collect the data which is necessary to create the results presentation
- Parameters:
nodes_data (dict) – dictionary containing all energy system components data from the input Excel File
results (dict) – oemof result object holding the return of the chosen solver
esys (solph.EnergySystem) – oemof energy system variable holding the energy system status before optimization used to reduce the dependency of the correctness of user’s input
result_path (str) – str holding the algorithms result path used for the energy system’s pipes data
variable_cost_factor (float) – factor that considers the data_preparation_algorithms, can be used to scale the results up for a year
- Returns:
comp_dict (dict) - dictionary containing the result parameters of all of the energy system’s components
total_demand (float) - float holding the energy system’s final energy demand
total_usage (float) - float holding the energy system’s secondary energy demand
- program_files.postprocessing.create_results_collecting_data.get_capacities(comp_type: str, comp_dict: list, results: dict, label: str) list[source]
method to get the components capacity which is component type specific
- Parameters:
comp_type (str) – str holding the component’s type
comp_dict (list) – list holding the energy system component’s information as specified in the main method collect_data
results (dict) – oemof result object holding the return of the chosen solver
label (str) – str holding the label which is necessary to determine the storage capacity
- Returns:
comp_dict (list) - returns the component’s parameter list after the capacity has been added
- program_files.postprocessing.create_results_collecting_data.get_comp_type(node) str[source]
method to declare the component type’s short form for the list of components (loc)
- Parameters:
node (different oemof solph components) – component under investigation
- Returns:
- (str) - str holding the component’s type which will be listed in the list of components (loc)
- program_files.postprocessing.create_results_collecting_data.get_flows(node, results: dict, esys: EnergySystem) list[source]
method to get component’s (nd) in- and outflows
- Parameters:
node (different oemof solph components) – component under investigation
results (dict) – oemof result object holding the return of the chosen solver
esys (solph.EnergySystem) – oemof energy system variable holding the energy system status before optimization used to reduce the dependency of the correctness of user’s input
- Returns:
- (list) - list of flow series of the considered component: [0] inflow 1, [1] inflow 2, [2] outflow 1, [3] outflow 2
- program_files.postprocessing.create_results_collecting_data.get_investment(node, esys: EnergySystem, results: dict, comp_type: str) float[source]
method used to obtain the component’s investment, this is calculated differently for storages compared to the other components
- Parameters:
node (different oemof solph components) – component under investigation
esys (solph.EnergySystem) – oemof energy system variable holding the energy system status before optimization used to reduce the dependency of the correctness of user’s input
results (dict) – oemof result object holding the return of the chosen solver
comp_type (str) – str holding the component’s type
- Returns:
- (float) - float containing the investment value of the considered component (node)
- program_files.postprocessing.create_results_collecting_data.get_max_invest(comp_type: str, node) float[source]
get the maximum investment capacity for the specified component (nd)
- Parameters:
comp_type (str) – str holding the component’s type
node (different oemof solph components) – component under consideration
- Returns:
max_invest (float) - float holding the maximum possible investment
- program_files.postprocessing.create_results_collecting_data.get_sequence(flow, component: dict, node, output_flow: bool, esys: EnergySystem) list[source]
method to get the in- and outflow’s sequences from the oemof produced structures
- Parameters:
flow (oemof.network.Inputs or Outputs) – oemof in or output data that essentially represent the properties of the edges of the graph.
component (dict) – energy system node’s information
node (different oemof solph components) – component under investigation
output_flow (bool) – boolean which decides rather the considered flows (flow) are output flows
esys (solph.EnergySystem) – oemof energy system variable holding the energy system status before optimization used to reduce the dependency of the correctness of user’s input
- Returns:
return_list (list) - list containing the found flows sequences
Postprocessing/create_results_prepare_data
Christian Klemm - christian.klemm@fh-muenster.de Gregor Becker - gregor.becker@fh-muenster.de Oscar Quiroga - oscar.quiroga@fh-muenster.de
- program_files.postprocessing.create_results_prepare_data.add_component_to_loc(label: str, comp_dict: list, df_list_of_components: DataFrame, variable_cost_factor: float, maxinvest='---') DataFrame[source]
adds the given component with it’s parameters to list of components (loc)
- Parameters:
label (str) – str containing the component’s label shown in list of components (loc)
comp_dict (list) – list holding the energy system component’s information as specified in the main method collect_data
df_list_of_components (pandas.DataFrame) – DataFrame containing the list of components which will be the components.csv afterwards
variable_cost_factor (float) – factor that considers the data_preparation_algorithms, can be used to scale the results up for a year
maxinvest (str) – str holding the maximum possible investment
- Returns:
df_list_of_components (pandas.DataFrame) - DataFrame containing the updated (new added line) list of components which will be the components.csv afterwards
- program_files.postprocessing.create_results_prepare_data.append_flows(label: str, comp_dict: list, df_result_table: DataFrame) DataFrame[source]
In this method, the time series of inflows and outflows as well as the capacities of the component (comp_dict) are appended to the data structure df_result_table. Here, each time series represents a column. This data structure is stored at the end of the result processing as file result.csv in the result folder of the model definition and represents the basis for the plotting in the GUI.
- Parameters:
label (str) – str containing the component’s label shown in list of components (loc)
comp_dict (list) – list holding the energy system component’s information as specified in the main method collect_data
df_result_table (pandas.DataFrame) – DataFrame containing the energy system’s flows which will be plotted within the GUI and exported in the result.csv file in the model definition’s result folder
- Returns:
df_result_table (pandas.DataFrame) - DataFrame containing the updated energy system’s flows (added new columns) which will be plotted within the GUI and exported in the result.csv file in the model definition’s result folder
- program_files.postprocessing.create_results_prepare_data.create_flow_info_dict(comp_dict: list) DataFrame[source]
Creates a DataFrame with flow information for each component.
Extracts up to two input and two output flow connections from a component dictionary. Each flow is represented as a tuple of buses (source, target). The result includes the component name and the identified flows.
- Parameters:
comp_dict (list) – List with component names as keys and flow data as values.
- Returns:
flow_info_df (pandas.DataFrame): A table with columns for component name and up to four flow tuples.
- program_files.postprocessing.create_results_prepare_data.prepare_data(comp_dict: dict, total_demand: float, nodes_data: dict, variable_cost_factor: float) Tuple[DataFrame, float, float, float, DataFrame, float][source]
This method is the main method of data preparation for subsequent export and/or display in the GUI of the energy system’s result data.
- Parameters:
comp_dict (dict) – dictionary holding the energy systems’ components data e.g. investment, periodical costs, etc.
total_demand (float) – float holding the energy systems final energy demand calculated based on the energy systems’ sinks
nodes_data (dict) – dictionary containing data from excel model definition file
variable_cost_factor (float) – factor that considers the data_preparation_algorithms, can be used to scale the results up for a year
- Returns:
df_list_of_components (pandas.DataFrame) - DataFrame containing the list of components which will be the components.csv afterwards
total_periodical_costs (float) - total periodical costs of the considered energy system
total_variable_costs (float) - total variable costs of the considered energy system
total_constrain_costs (float) - total constraint costs of the considered energy system
df_list_of_components (pandas.DataFrame) - DataFrame containing the energy system’s flows which will be plotted within the GUI and exported in the result.csv file in the model definition’s result folder
total_demand (float) - total final energy demand of the considered energy system
- program_files.postprocessing.create_results_prepare_data.prepare_loc(comp_dict: dict, df_result_table: DataFrame, df_list_of_components: DataFrame, variable_cost_factor: float) Tuple[DataFrame, float, float, float, DataFrame][source]
In this method, on the one hand, the components as well as their flows are added to the list of components (loc) and to the df_result_table and, on the other hand, the costs (variable and periodic) as well as emissions of the energy system are balanced.
- Parameters:
comp_dict (dict) – dictionary holding the energy systems’ components data e.g. investment, periodical costs, etc.
df_result_table (pandas.DataFrame) – DataFrame containing the energy system’s flows which will be plotted within the GUI and exported in the result.csv file in the model definition’s result folder
df_list_of_components (pandas.DataFrame) – DataFrame containing the list of components which will be the components.csv afterwards
variable_cost_factor (float) – factor that considers the data_preparation_algorithms, can be used to scale the results up for a year
- Returns:
df_list_of_components (pandas.DataFrame) - DataFrame containing the list of components which will be the components.csv afterwards
total_periodical_costs (float) - total periodical costs of the considered energy system
total_variable_costs (float) - total variable costs of the considered energy system
total_constrain_costs (float) - total constraint costs of the considered energy system
df_list_of_components (pandas.DataFrame) - DataFrame containing the energy system’s flows which will be plotted within the GUI and exported in the result.csv file in the model definition’s result folder
Postprocessing/plotting
Gregor Becker - gregor.becker@fh-muenster.de Janik Budde - janik.budde@fh-muenster.de
- program_files.postprocessing.plotting.add_value_to_amounts_dict(label: str, value_am: float, amounts_dict: dict) dict[source]
Adds the value_am to the given amounts dict by checking if the chosen label is already part of the amounts dict (append) or not (create new dict entry).
- Parameters:
label (str) – dict key which will be updated or added
value_am (dict) – value which will be appended to the label’s list in the amounts dict
amounts_dict (dict) – dictionary holding the already collected energy amounts
- Returns:
amounts_dict (dict) - amounts dict after the new value was added
- program_files.postprocessing.plotting.collect_pareto_data(result_dfs: dict, result_path: str) None[source]
In this method, the data is prepared for plotting a pareto curve.
- Parameters:
result_dfs (dict) – dictionary containing the energy systems’ components.csv
result_path (str) – path where the pareto plot will be stored
- program_files.postprocessing.plotting.create_sink_differentiation_dict(model_definition: DataFrame) dict[source]
use the model_definitions sink sheet to create a dictionary holding the sink’s type as well as it’s label
- Parameters:
model_definition (pandas.DataFrame) – sinks sheet of the investigated model definition
- Returns:
sink_types (dict) - dictionary holding the energy systems’ sinks types after a distinction based on the sector column has been done
- program_files.postprocessing.plotting.dict_to_dataframe(amounts_dict: dict, return_df: DataFrame) DataFrame[source]
Method to convert the dictionary with the collected data of a Pareto point to a row of return_df.
- Parameters:
amounts_dict (dict) – dictionary holding the previously collected data of the energy systems’ components
return_df (pandas.DataFrame) – DataFrame to which the new pareto point’s row will be added
- Returns:
return_df (pandas.DataFrame) - DataFrame holding the amounts of the already considered pareto points (within this method a new row has been added)
- program_files.postprocessing.plotting.get_dataframe_from_nodes_data(nodes_data: dict) DataFrame[source]
Within this method the nodes_data DataFrames are combined to one big DataFrame holding all the active components of the studied energy system.
- Parameters:
nodes_data (dict) – dictionary holding the model definition’s spreadsheet data
- Returns:
- (pandas.DataFrame) - one big DataFrame holding all active components of the studied energy system
- program_files.postprocessing.plotting.get_pv_st_dir(c_dict: dict, value: float, comp_type: str, comp: Series) dict[source]
This method creates an entry in the dictionary c_dict associated with the cardinal direction for the PV or ST system under consideration and returns it to the plotting.
Note
This method only works for azimuth between 0° and 360°. Please make sure not to use -180° - 180°.
- Parameters:
c_dict (dict) – component dictionary holding the PV or ST cardinal specific values
value (float) – value which will be appended regarding it’s cardinal direction to the dictionary c_dict
comp_type (str) – String that is used to distinguish whether it is a PV or an ST plant.
comp (pandas.Series) – Series holding the nodes data row of the investigated component
- Returns:
c_dict (dict) - dictionary holding the PV or ST cardinal specific values which was updated within this method
- program_files.postprocessing.plotting.get_value(label: str, column: str, dataframe: DataFrame) float[source]
Method to locate the values of a given column from the given dataframe while the row location is driven by the components ID (label).
- Parameters:
label (str) – string holding the component’s ID (label)
column (str) – string holding the searched column label
dataframe (pandas.DataFrame) – DataFrame in which the values will be searched
- Returns:
- (float) - float representing the value of the investigated row’s (label) column
Postprocessing/plotting_elec_amounts
Gregor Becker - gregor.becker@fh-muenster.de
- program_files.postprocessing.plotting_elec_amounts.battery_storage_electricity_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ battery storage losses
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new battery loss values
- program_files.postprocessing.plotting_elec_amounts.collect_electricity_amounts(dataframes: dict, nodes_data: dict, result_path: str, sink_known: dict) None[source]
main function of the algorithm to collect the electricity amounts of the investigated energy system for later plotting within the GUI
- Parameters:
dataframes (dict) – dictionary which holds the results of the pareto optimization - structure {str(share of emission reduction between 0 and 1): pandas.DataFrame(components.csv)}
nodes_data (pandas.DataFrame) – DataFrame containing all components defined within the input model definition file
result_path (str) – str which defines the folder where the elec_amount plot will be saved
sink_known (dict) – dictionary which defines the type of the energy system’s sinks structure {sink_label: [bool(elec), bool(heat), bool(cooling)]}
- program_files.postprocessing.plotting_elec_amounts.generic_transformer_electricity_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ electricity flow of generic transformer components (e.g. CHP outputs or electric heating components).
Note
It is always assumed that the components are driven electrically, so that the first output is an electricity output and the second is a heat output.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new electricity flows of generic transformer components.
- program_files.postprocessing.plotting_elec_amounts.get_electric_timeseries_sources(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
method which is used to get the electric timeseries sources output as well as the output buses excess
- Parameters:
components_df (pandas.DataFrame) – dataframe containing the nodes data’s entries
dataframe (pandas.DataFrame) – dataframe containing the considered pareto point’s result (components.csv)
amounts_dict (dict) – dictionary holding the collected electricity amounts for all pareto points
- Returns:
amounts_dict (dict) - dictionary holding the collected electricity amounts for all pareto points within this method the new timeseries source entries were collected
- program_files.postprocessing.plotting_elec_amounts.get_electric_windpower_sources(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
method which is used to get the windpower sources output as well as the output buses excess
- Parameters:
components_df (pandas.DataFrame) – dataframe containing the nodes data’s entries
dataframe (pandas.DataFrame) – dataframe containing the considered pareto point’s result (components.csv)
amounts_dict (dict) – dictionary holding the collected electricity amounts for all pareto points
- Returns:
amounts_dict (dict) - dictionary holding the collected electricity amounts for all pareto points within this method the new timeseries source entries were collected
- program_files.postprocessing.plotting_elec_amounts.get_electricity_excess(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict)[source]
Collecting the energy systems’ electricity excess bus.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new electricity excess values
- program_files.postprocessing.plotting_elec_amounts.get_grid_import(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict)[source]
Collecting the energy systems’ electricity grid import.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new grid import values
- program_files.postprocessing.plotting_elec_amounts.get_heat_pump_electricity_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ heat pumps flow data.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new heat pump values
- program_files.postprocessing.plotting_elec_amounts.get_st_electricity_amounts(components_df: DataFrame, amounts_dict: dict, dataframe: DataFrame) dict[source]
method which is used to get the electric demand of solar thermal flat plates
- Parameters:
components_df (pandas.DataFrame) – dataframe containing the nodes data’s entries
dataframe (pandas.DataFrame) – dataframe containing the considered pareto point’s result (components.csv)
amounts_dict (dict) – dictionary holding the collected electricity amounts for all pareto points
- Returns:
amounts_dict (dict) - dictionary holding the collected electricity amounts for all pareto points within this method the new timeseries source entries were collected
- program_files.postprocessing.plotting_elec_amounts.pv_electricity_amount(components_df: DataFrame, pv_st: str, dataframe: DataFrame, amounts_dict: dict) dict[source]
method which is used to get the pv system earnings in total and azimuth specific as well as the output buses excess
- Parameters:
components_df (pandas.DataFrame) – dataframe containing the nodes data’s entries
pv_st (str) – str defining rather the algorithm searches for photovoltaic or solar thermal entries
dataframe (pandas.DataFrame) – dataframe containing the considered pareto point’s result (components.csv)
amounts_dict (dict) – dictionary holding the collected electricity amounts for all pareto points
- Returns:
amounts_dict (dict) - dictionary holding the collected electricity amounts for all pareto points within this method the new PV entries were collected
- program_files.postprocessing.plotting_elec_amounts.sink_electricity_amounts(components_df: DataFrame, sink_known: dict, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ electricity sinks flow data.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
sink_known (dict) – dictionary which defines the type of the energy systems’ sinks structure {sink_label: [bool(elec), bool(heat), bool(cooling)]}
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new electricity sink values
Postprocessing/plotting_heat_amounts
Gregor Becker - gregor.becker@fh-muenster.de
- program_files.postprocessing.plotting_heat_amounts.collect_heat_amounts(dataframes: dict, nodes_data: dict, result_path: str, sink_known: dict) None[source]
main function of the algorithm to collect the heat amounts of the investigated energy system for later plotting within the GUI
- Parameters:
dataframes (dict) – dictionary which holds the results of the pareto optimization - structure {str(share of emission reduction between 0 and 1): pandas.DataFrame(components.csv)}
nodes_data (pandas.DataFrame) – DataFrame containing all components defined within the input scenario file
result_path (str) – str which defines the folder where the elec_amount plot will be saved
sink_known (dict) – dictionary which defines the type of the energy system’s sinks structure {sink_label: [bool(elec), bool(heat), bool(cooling)]}
- program_files.postprocessing.plotting_heat_amounts.dh_heat_amounts(dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ district heating consumer demands
- Parameters:
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new district heating consumer demands
- program_files.postprocessing.plotting_heat_amounts.generic_transformer_heat_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ heat flow of generic transformer components (e.g. CHP outputs or electric heating components).
Note
It is always assumed that the components are driven electrically, so that the first output is an electricity output and the second is a heat output.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new heat flows of generic transformer components.
- program_files.postprocessing.plotting_heat_amounts.get_heat_excess(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict)[source]
Collecting the energy systems’ heat excess bus.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new heat excess values
- program_files.postprocessing.plotting_heat_amounts.heat_pump_heat_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ heat pumps flow data.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new heat pump values
- program_files.postprocessing.plotting_heat_amounts.insulation_heat_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ insulation heat compensation amounts
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new insulation compensation amounts
- program_files.postprocessing.plotting_heat_amounts.sink_heat_amounts(components_df: DataFrame, sink_known: dict, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ heat sinks flow data.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
sink_known (dict) – dictionary which defines the type of the energy systems’ sinks structure {sink_label: [bool(elec), bool(heat), bool(cooling)]}
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new heat sink values
- program_files.postprocessing.plotting_heat_amounts.st_heat_amount(components_df: DataFrame, pv_st: str, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the Solar thermal flat plates output flows within the amounts_dict[“ST”] entry. Additionally a cardinal orientation distinction is made in the amounts_dict[“ST_north”], amounts_dict[“ST_west”], etc. is made.
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
pv_st (str) – string holding the technology of the components to be collected
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new ST values
- program_files.postprocessing.plotting_heat_amounts.thermal_storage_heat_amounts(components_df: DataFrame, dataframe: DataFrame, amounts_dict: dict) dict[source]
Collecting the energy systems’ thermal storage losses
- Parameters:
components_df (pandas.DataFrame) – DataFrame containing all components of the studied energy system
dataframe (pandas.DataFrame) – dataframe holding the energy systems’ result flows
amounts_dict (dict) – dictionary holding the already collected flow values of the studied energy system
- Returns:
amounts_dict (dict) - dictionary holding the energy systems’ flow amounts which was expanded within this method by new thermal loss values